




文章摘要(AI生成)
通过使用慢查询日志功能,可以获取执行时间较长的SQL语句并查看执行计划,然后通过show profile来查看SQL的性能使用情况,进而进行优化。开启慢查询日志需要在配置文件中添加相关参数,并使用mysqldumpslow工具分析慢查询日志。同时,通过explain查看SQL执行计划进行优化,包括合理创建索引、避免全表扫描、优化order by、group by语句以及避免使用count( * )等。此外,在关联表时建立索引、避免使用not in语句等也是优化的关键。通过以上方法,可以提高SQL查询的性能,减少查询时间,提升数据库性能。
优化思路:
- 首先需要使用【慢查询日志】功能,去获取所有查询时间比较长的SQL语句
- 查看执行计划,查看有问题的SQL的执行计划
- 针对查询慢的SQL语句进行优化
- 使用
show profile[s]查看有问题的SQL的性能使用情况
慢查询日志
慢查询开启通过在配置文件中添加:
slow_query_log=ON
long_query_time=1
开启后在对应的mysql数据存储路径中可以找到慢查询日志:
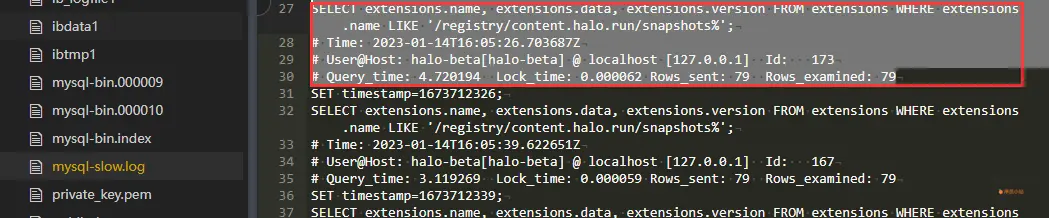
每条sql语句,都记录了对应的执行时的系统时间,用户和连接信息,以及对应的查询耗时(Query_time),等待表锁耗时(Lock_time),查询返回行数(Rows_sent),查询扫描行数(Rows_examined)。
使用mysqldumpslow工具可以分析慢查询日志,例如按查询时间,筛选出最慢的10条查询语句:
/www/server/mysql/bin/mysqldumpslow -s t -t 10 -g "SELECT" /www/server/data/mysql-slow.log
得到结果如下:

其它可用参数如下:
-v |
版本信息 |
|---|---|
-d |
debug |
-s |
排序条件,默认使用at. al:平均锁定时间;ar:平均返回记录时间;at:平均查询时间;c:数量;l:锁定时间;r:返回记录时间;t:查询时间 |
-r |
逆序排序(只对结果排序) |
-t |
展示前n条记录 |
-a |
查询所有具体sql,即不抽象sql中的条件值 |
-n |
名称中至少包含 n 位数字的抽象数字 |
-g |
正则表达式匹配搜索 |
-i |
服务器实例的名称(如果使用 mysql.server 启动脚本) |
-l |
不要从总时间中减去锁定时间 |
执行计划
通过explain查看sql执行计划,来对sql进行优化:
- id: SELECT 查询的标识符. 每个 SELECT 都会自动分配一个唯一的标识符.
- select_type: SELECT 查询的类型. 比如普通查询、联合查询(union、union all)、子查询(subquery)等复杂查询。
- table: 查询的是哪个表
- partitions: 匹配的分区
- type: join 类型。从好到差依次为system、const、eq_ref、fulltext、ref_or_null、unique_subquery、index_subquery、range、index_merge、index、ALL
- system:表中只有一行数据或者为空表
- const:使用唯一索引或主键。返回记录一定是1行记录的等值where条件时,通常type是const。
- eq_ref:唯一性索引扫描。对于每个索引键,表中只有一条记录与之匹配
- ref:非唯一性索引扫描,返回多个匹配条件的行。
- range:索引范围扫描
- index:结果列中使用到了索引
- all:全表扫描数据文件
- possible_keys: 此次查询中可能选用的索引
- key: 此次查询中确切使用到的索引.
- key_len: 索引长度,长度越小,效率越高
- ref: 哪个字段或常数与 key 一起被使用
- rows: 显示此查询一共扫描了多少行. 这个是一个估计值.
- filtered: 表示此查询条件所过滤的数据的百分比
- extra: 额外的信息
- using index:查询时不需要回表查询,直接通过索引就可以获取查询的结果数据。
- using where:Mysql将对storage engine提取的结果进行过滤,过滤条件字段无索引。
sql语句优化
索引优化
- 为搜索字段(where中的条件)、排序字段、select查询列,创建合适的索引,不过要考虑数据的业务场景:查询多还是增删多?
- 尽量建立组合索引并注意组合索引的创建顺序,按照顺序组织查询条件、尽量将筛选粒度大的查询 条件放到最左边。
- 尽量使用覆盖索引,SELECT语句中尽量不要使用。
- order by、group by语句要尽量使用到索引
- 索引长度尽量短,短索引可以节省索引空间,使查找的速度得到提升,同时内存中也可以装载更多 的索引键值。太长的列,可以选择建立前缀索引
- 索引更新不能频繁,更新非常频繁的数据不适宜建索引,因为维护索引的成本。
- order by的索引生效,order by排序应该遵循最佳左前缀查询,如果是使用多个索引字段进行排序,那么排序的规则必须相同(同是升序或者降序),否则索引同样会失效。
limit优化
- 如果预计SELECT语句的查询结果是一条,最好使用 LIMIT 1,可以停止全表扫描。
- 处理分页会使用到LIMIT ,当翻页到非常靠后的页面的时候,偏移量会非常大,这时LIMIT的效率会非常差。 LIMIT的优化问题,其实是OFFSET的问题,它会导致MySql扫描大量不需要的行然后再抛弃掉。 解决方案:单表分页时,使用自增主键排序之后,先使用where条件 id > offset值,limit后面只写rows
其他优化
- 小表驱动大表,建议使用left join时,以小表关联大表,因为使用join的话,第一张表是必须全扫描的,以少关联多就可以减少这个扫描次数。
- 避免全表扫描,mysql在使用不等于(!=或者<>)的时候无法使用索引导致全表扫描。在查询的时候,如果对索引使用不等于的操作将会导致索引失效,进行全表扫描
- 避免mysql放弃索引查询,如果mysql估计使用全表扫描要比使用索引快,则不使用索引。(最典型的场景就是数据量少的时候) 尽量不使用count( * )、尽量使用count(主键)
- JOIN两张表的关联字段最好都建立索引,而且最好字段类型是一样的。
- WHERE条件中尽量不要使用not in语句(建议使用not exists)
- 合理利用慢查询日志、explain执行计划查询、show profile查看SQL执行时的资源使用情况。
profile分析sql
开启profile:

查看sql分析列表,分析sql执行情况:




评论区