




文章摘要(AI生成)
随着计算机系统复杂性的增加,传统编程模式在高并发和数据密集型任务中显现出局限性。响应式编程(Reactive Programming)通过异步、非阻塞和事件驱动的方式来处理数据流,从而显著提升系统的性能和可扩展性。与之相比,阻塞式编程要求客户端在发送请求后,必须等待服务端的响应,如果处理时间过长,会导致客户端阻塞,从而影响系统吞吐量。大部分时间内,线程处于等待I/O状态,造成CPU资源浪费。这种编程方式适用于低并发和小规模应用,但在高并发环境下效果不佳。因此,响应式编程成为提升系统性能的有效解决方案,特别是在面对现代应用需求时,展现了更好的适应性和效能。
引言
随着计算机系统的规模和复杂性不断增加,传统的编程模式在处理高并发、数据密集型任务时暴露出明显的局限性。响应式编程(Reactive Programming) 通过 异步、非阻塞、事件驱动 的方式处理数据流,能够显著提高系统的性能和可扩展性。
阻塞式编程
阻塞式编程中,客户端的请求与服务端的响应是阻塞的,对于客户端来说,必须在发送请求后阻塞等待服务端的响应结果:
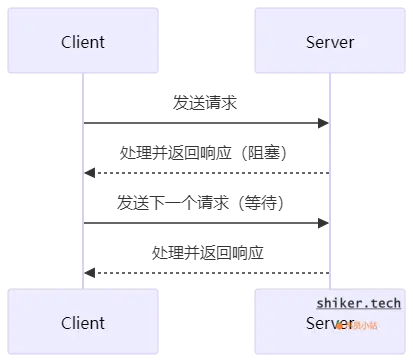
特点:
- 每个请求必须等待前一个请求完成后才能执行。
- 如果 Server 处理慢,会导致 Client 阻塞,影响系统吞吐量。
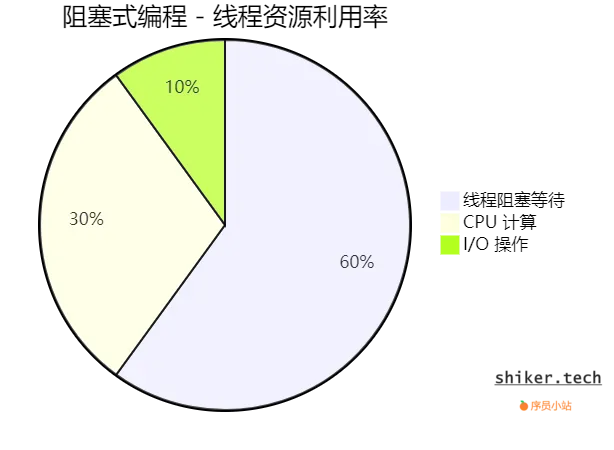
- 大部分时间 线程在等待 I/O,造成 CPU 资源浪费。适用于低并发、小规模应用。
响应式编程
响应式编程则在客户端发送请求后,不再阻塞等待服务端返回结果,而是直接发送下一个请求,在服务端发送响应结果时进行异步处理
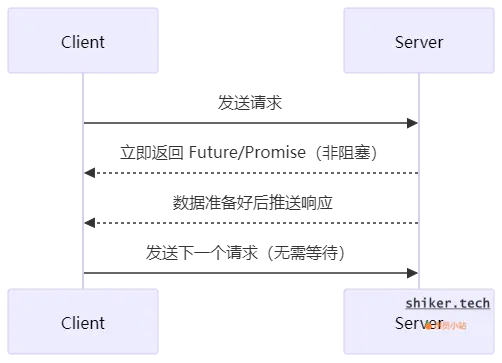
特点:
- Server 处理请求时不会阻塞,Client 可以并行执行其他任务。
- 提高系统吞吐量,降低线程资源消耗。
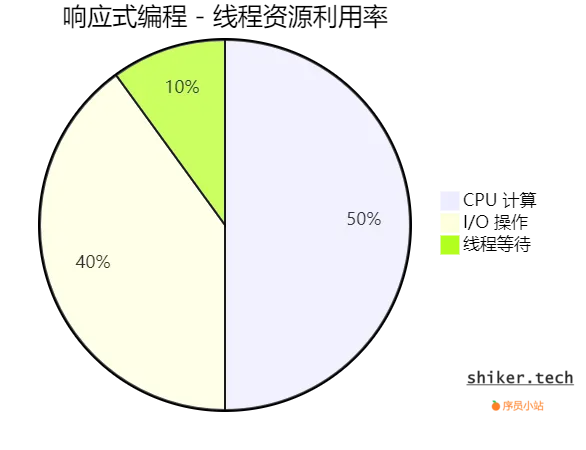
- 通过 非阻塞 I/O 和 事件驱动模型,减少线程等待,提高 CPU 利用率。适用于 高并发、高吞吐量 场景.
两者对比
传统阻塞式编程与响应式编程特性不同:
| 特性 | 传统阻塞式编程 (Synchronous) | 响应式编程 (Reactive) |
|---|---|---|
| 执行方式 | 同步,任务按顺序执行 | 异步,任务可并行执行 |
| 线程模型 | 一个任务占用一个线程 | 事件驱动,少量线程处理大量任务 |
| 资源利用率 | 线程阻塞,资源浪费 | 线程复用,资源利用率高 |
| 适用场景 | 低并发、小规模应用 | 高并发、流式数据处理 |
| 响应速度 | 需要等待前一个任务完成 | 任务可并行,提高响应速度 |
| 背压处理 | 无法控制生产者速率 | 背压机制可控 |
Reactive Streams 是什么?
概念与目标
Reactive Streams 是 Java 平台上的 异步流处理标准,它定义了一组接口,用于在异步数据流处理过程中提供 背压(Backpressure) 机制。
主要目标:
- 标准化异步流处理,提供通用的 Publisher-Subscriber 模型。
- 内置背压机制,防止消费者过载,提升系统稳定性。
- 促进库间互操作性,让不同响应式框架(如 RxJava、Reactor、Akka Streams)能够兼容。
解决的问题
异步数据流处理
在传统的同步模式下,数据流必须 等待前一步完成后 才能继续,导致性能瓶颈。Reactive Streams 采用 异步、事件驱动 的方式,使数据流可以并行 处理,提高吞吐量。
示例:传统阻塞式 vs. 响应式流
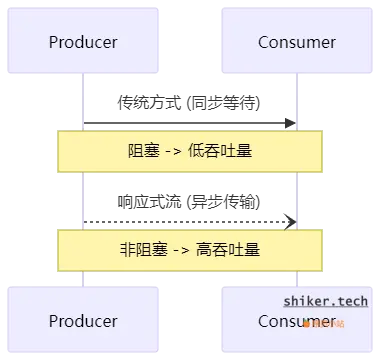
背压(Backpressure)机制
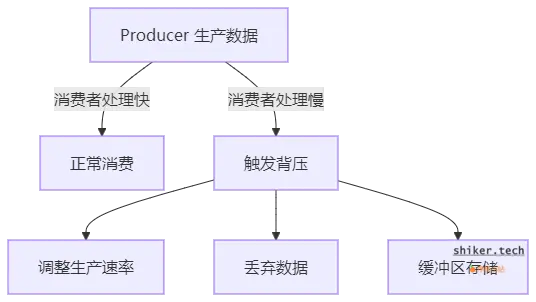
如果生产者(Producer)速度远快于消费者(Consumer),传统模型可能出现 OOM、数据丢失 或 处理延迟 等问题。
Reactive Streams 的解决方案:
- 消费者按需请求,只有在有能力处理时才获取数据。
- 生产者可动态调整速率,防止数据积压。
- 支持缓冲、丢弃、降速等策略,提高系统稳定性。
背压机制流程
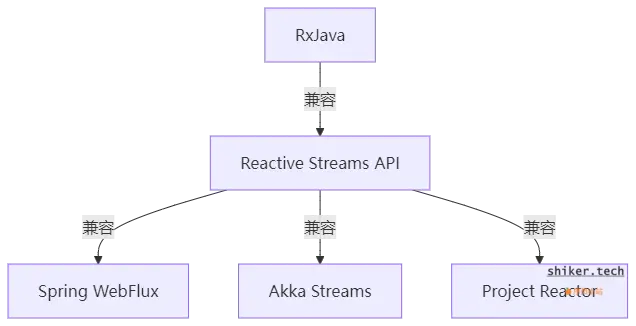
互操作性
在 JVM 生态中,很多响应式库(如 RxJava、Reactor、Akka Streams)采用不同的 API,导致兼容性问题。Reactive Streams 提供了一组 标准接口(如 Publisher、Subscriber),使不同库之间可以 无缝集成。
适用场景
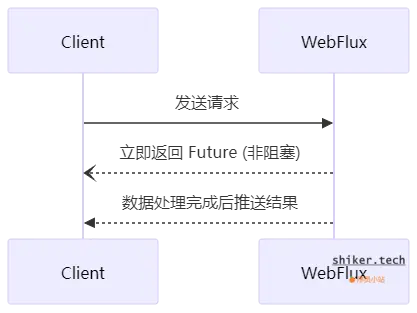
高吞吐 API(如 WebFlux)
在高并发 Web 应用中,传统的阻塞式请求模型(Servlet)容易因线程阻塞而导致性能下降。Reactive Streams 在 WebFlux(Spring 5+)中的应用,使服务器可以 非阻塞 处理请求,提高吞吐量。
适用场景:
✅ RESTful API 服务
✅ 需要处理高并发请求的 Web 应用
消息驱动系统(Kafka、RabbitMQ)
在 消息队列(MQ) 场景下,生产者可能比消费者快,传统同步模型可能会丢失消息 或 消息堆积。使用 Reactive Streams,消费者可以按需拉取,避免压力过载。
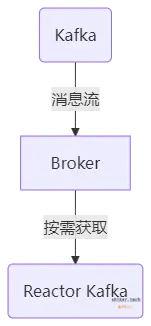
适用场景:
✅ 高吞吐消息处理
✅ Kafka、RabbitMQ 等事件驱动架构
数据流处理(如 Spark Streaming、Flink)
在 实时数据分析 场景中,传统批处理方式可能存在 延迟,而 Reactive Streams 允许 数据以流的方式实时传输和计算。
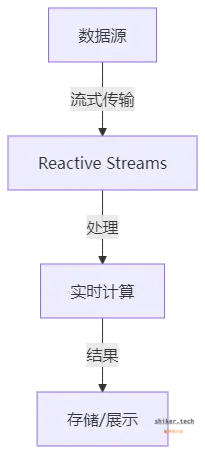
适用场景:
✅ 日志流分析
✅ 物联网(IoT)数据流处理
✅ 股票交易数据流
Reactive Streams 规范与核心接口
核心接口
Reactive steams提供了四个API组件:
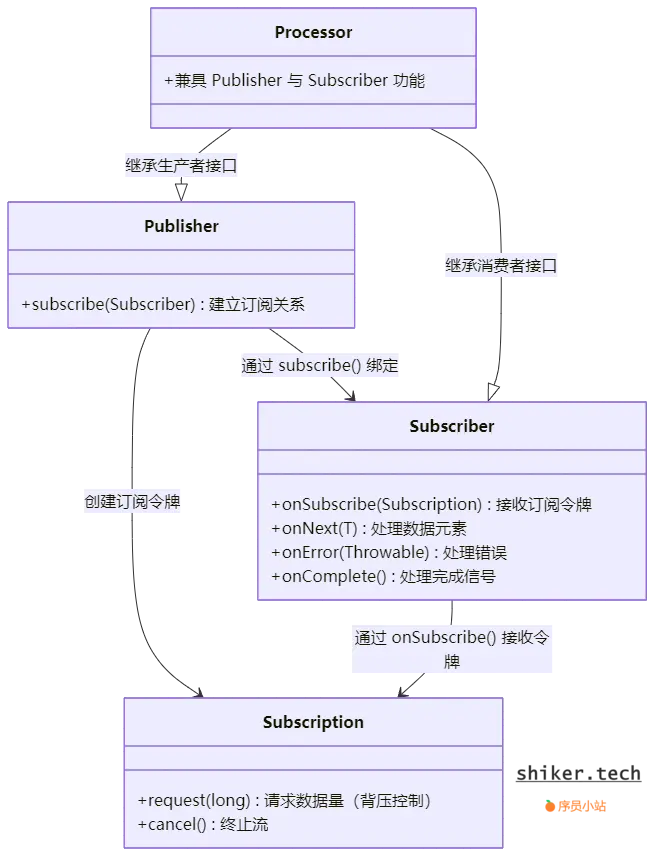
Publisher<T>(发布者)
Publisher 是数据流的源头,负责生成并发布数据元素。它向订阅者(Subscriber)发送订阅请求,并根据订阅者的需求推送数据。Publisher 的关键方法包括:
void subscribe(Subscriber<? super T> s):订阅方法,订阅者调用此方法以订阅发布者。
Subscriber<T>(订阅者)
Subscriber 是数据的消费者,接收并处理来自发布者的数据。它通过订阅关系(Subscription)与发布者交互,控制数据的接收速率。Subscriber 的主要方法包括:
void onSubscribe(Subscription s):当订阅成功时调用,传入订阅关系。void onNext(T t):接收下一个数据元素。void onError(Throwable t):处理数据流中的错误。void onComplete():当数据流完成时调用。
Subscription(订阅关系)
Subscription 管理发布者与订阅者之间的关系,允许订阅者控制数据流的速率,防止过载。其核心方法包括:
void request(long n):请求n个数据元素。void cancel():取消订阅,停止接收数据。
Processor<T, R>(处理器)
Processor 同时实现了 Subscriber 和 Publisher 接口,充当数据处理的中间层,既能接收数据,又能发布处理后的数据。这使得数据流可以在多个处理步骤中进行转换和操作。
数据流转
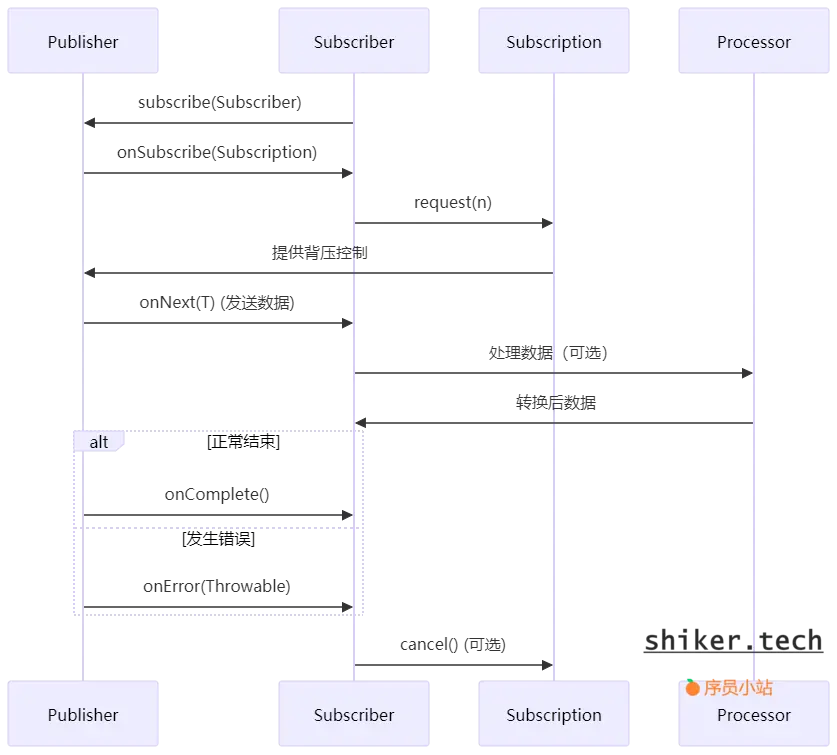
数据的流转遵循 订阅 -> 请求 -> 处理 -> 终止 的流程。具体步骤如下:
- 订阅阶段:
Subscriber订阅Publisher,调用Publisher.subscribe(Subscriber)方法。Publisher创建Subscription并传递给Subscriber.onSubscribe(Subscription)。
- 数据请求阶段(背压控制):
Subscriber通过Subscription.request(n)请求数据,决定消费速率。Publisher根据请求数量n发送数据。
- 数据处理阶段:
Publisher调用Subscriber.onNext(T)发送数据。Subscriber处理接收到的数据。
- 终止阶段:
- 当数据流结束时,
Publisher调用Subscriber.onComplete()。 - 如果发生错误,调用
Subscriber.onError(Throwable)处理异常。 Subscriber可调用Subscription.cancel()取消订阅,停止接收数据。
- 当数据流结束时,
其调用流程图如下:
背压(Backpressure)机制解析
什么是背压?
背压(Backpressure)是 控制生产者与消费者速率不匹配 的机制,确保数据处理系统不会因数据过载而崩溃。
问题:
- 生产者速度 > 消费者处理能力:数据堆积,导致内存溢出(OOM)。
- 消费者速度 > 生产者:处理能力闲置,浪费资源。
解决方案:
Reactive Streams 提供 Subscription.request(n) 方法,允许消费者按需请求数据,以防止过载。
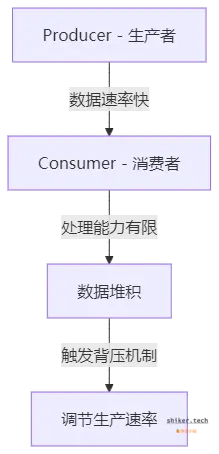
背压的几种策略
Reactive Streams 提供了多种策略来处理数据过载问题:
| 策略 | 说明 | 适用场景 |
|---|---|---|
| 丢弃(Drop) | 丢弃多余数据,仅保留部分数据 | 适用于非关键数据流,如日志采集 |
| 缓冲(Buffer) | 将数据存入缓冲区,稍后处理 | 适用于处理延迟可接受的任务,如批量日志分析 |
| 最新值替换(Latest) | 丢弃旧数据,仅保留最新数据 | 适用于实时系统,如股票行情更新 |
| 按需请求(Request-N) | 仅在消费者请求时发送数据 | 适用于严格控制流速的场景,如数据库查询 |
背压策略流程图:

Reactive Streams 如何实现背压?
在 Reactive Streams 中,背压是通过 Subscription.request(n) 方法实现的:
Subscriber通过onSubscribe(Subscription)订阅Publisher。Subscriber通过Subscription.request(n)按需请求数据。Publisher仅按n的数量发送数据,不会超量投递。
代码示例:
publisher.subscribe(new Subscriber<Integer>() {
private Subscription subscription;
@Override
public void onSubscribe(Subscription s) {
this.subscription = s;
s.request(5); // 仅请求 5 个数据,避免过载
}
@Override
public void onNext(Integer item) {
System.out.println("Received: " + item);
}
@Override
public void onError(Throwable t) {
System.err.println("Error: " + t.getMessage());
}
@Override
public void onComplete() {
System.out.println("Data stream completed.");
}
});
实际调用时,就会通过设置令牌来限制请求数:
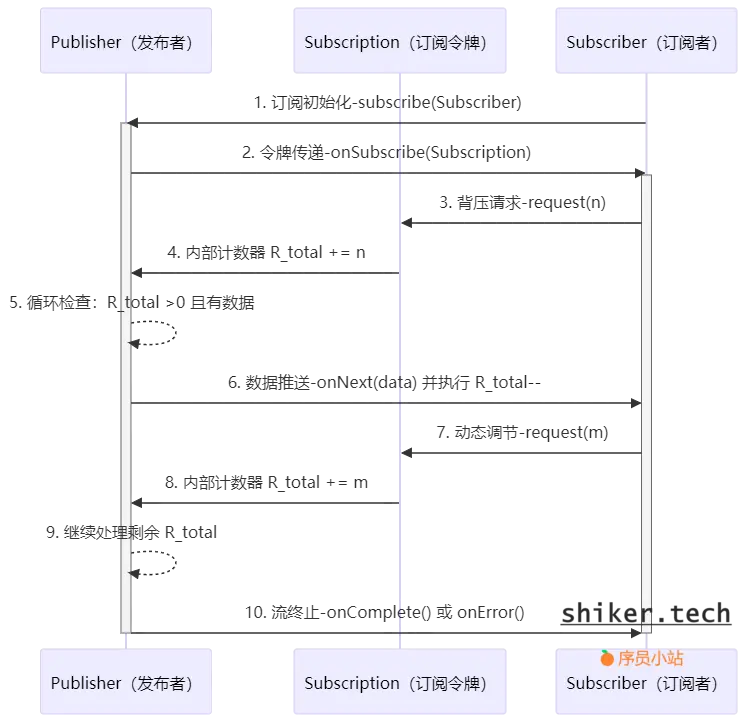
结尾
在本篇文章中,我们深入探讨了 Reactive Streams 的核心概念,包括它的目标、适用场景以及它的背压机制。我们还通过代码示例展示了如何在 Reactive Streams 中使用响应式流处理数据。响应式编程为现代高并发、高吞吐的应用程序提供了强大的能力,使得数据流的处理更加高效、灵活。
然而,响应式编程并不是银弹,它也带来了新的挑战,比如 背压管理、错误处理、资源泄漏 等问题。在下一篇文章中,我们将深入探讨 Reactive Streams 在实际开发中的挑战,并分享如何优化响应式流的性能,以确保应用的稳定性和可维护性。



评论区