




文章摘要(AI生成)
本文探讨了在保存博客文章时,由于包含 Emoji 或特殊字符而导致 MongoDB 报错的问题。作者在尝试保存文章时,遭遇了 `DataIntegrityViolationException` 异常,经过调试发现,问题源于使用 `substring` 方法截取字符串时,导致 Emoji 的代理对被截断,产生了不合法的 UTF-8 编码。由于 Java 的字符串是基于 UTF-16 编码,普通字符和高位字符(如 Emoji)在内部表示上有所不同,因此简单的字符截断容易导致非法字符出现。为了解决这一问题,作者建议使用 Unicode 码点进行截断,以确保字符串按完整字符处理。通过使用相关 API,如 `codePointCount()` 和 `offsetByCodePoints()`,可以有效避免截断问题,从而确保在保存到 MongoDB 时不会出现编码错误。整体而言,文章强调了处理字符串时需关注字符边界,以提高开发体验。
一、问题现象:文章保存时报错,Emoji 是幕后黑手
一个风和日丽的周日,我像往常一样打算“水”一篇博客文章,结果在文章保存的最后一步,系统却抛出了一个莫名其妙的异常:
org.springframework.dao.DataIntegrityViolationException: text contains invalid UTF-8;
nested exception is com.mongodb.MongoWriteException: text contains invalid UTF-8
我的博客系统在保存文章时,会截取正文前 150 个字符作为摘要。
我先梳理了我这个页面保存文章的流程:
- 先使用
StringUtils.substring(text, 0, 150)截取摘要; - 当文本中含 Emoji 或特殊符号时,MongoDB 报错
text contains invalid UTF-8; - 数据写入失败,前端提示保存失败。
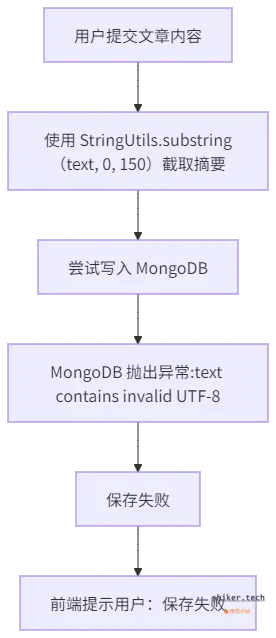
但是我乍一看,盲猜是 MongoDB 报了错,还是 UTF-8 编码不合法。难道是 MongoDB 配置有问题?难道是 Java 字符串没处理好?
于是我升级了mongoDB的驱动和数据库版本,但是还是报错!然后我怀疑可能是我的文本有问题,然后我把目录删掉,结果就保存成功了~
那看来问题出在我的文章目录这块儿,下面我来跟大伙儿看看这是个怎么个事!~
二、问题复现:原始文本 + 常见截断 = 崩
我的目录是这样子的(已简化):
一、JEP 181:嵌套类访问更自然、安全、简洁
🧨 现实中的问题
✅ JEP 181 的解决方案
👨💻对开发者的影响
💡 实际开发感知点
二、JEP 309:常量也能“懒加载”,class 更轻更快
🎯 现实中的问题
✅ JEP 309 的解决方案
💡 应用示例:编译器生成 Record 类常量
👨💻对开发者的影响
🧩 实际感知场景
三、总结:JVM 的细节革新,正在默默提升你的开发体验
📌 延伸阅读
当用 substring 截断前 150 个字符时,就会出现下面这种情况:
public static void main(String[] args) {
File file = new File("D:\\project\\problem\\src\\test.txt");
StringBuilder rawContent = new StringBuilder();
try (BufferedReader br = new BufferedReader(new FileReader(file))) {
String line;
while ((line = br.readLine()) != null) {
rawContent.append(line);
}
} catch (IOException e) {
e.printStackTrace();
}
// 直接按字符截断
System.out.println(rawContent.substring(0, 150));
}
///---结果输出---
一、JEP 181:嵌套类访问更自然、安全、简洁🧨 现实中的问题✅ JEP 181 的解决方案👨💻 对开发者的影响💡 实际开发感知点二、JEP 309:常量也能“懒加载”,class 更轻更快🎯 现实中的问题✅ JEP 309 的解决方案💡 应用示例:编译器生成 Record 类常量?
输出结果中,文本末尾出现了乱码,甚至是一个孤立的问号(通常是非法字符的替代显示),也正是这个非法字符导致了 MongoDB 写入失败。
三、根因分析:Emoji 被“截断了一半”
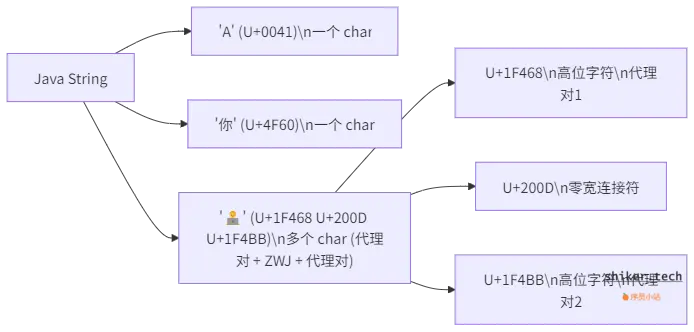
3.1 Java 字符串编码机制
- Java 中的
String是基于 UTF-16 编码的。 - 普通字符用一个
char表示;但 Unicode 中的高位字符(如 Emoji)会被编码成 两个 char(即代理对)。 - 示例:
"👨💻"实际由多个char组成。
我们用一张图做下总结:
3.2 substring 的陷阱
substring(0, 150)是基于char的索引;- 如果第 150 个字符恰好处于代理对的中间,截断后会只保留半个 Emoji;
- 这半个字符在 Java 中也许不会报错,但当写入 MongoDB 时,它会被转成 UTF-8,此时就变成了非法编码。
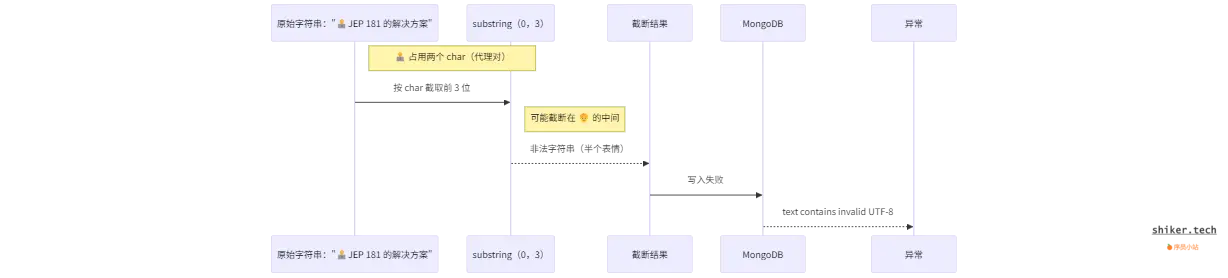
3.3 MongoDB 的 UTF-8 严格验证
- MongoDB 要求所有字符串必须是合法的 UTF-8;
- 如果存在未闭合的代理对,转换成 UTF-8 后就不合法,MongoDB 拒绝写入,抛出异常。
四、解决方案:用码点截断,尊重字符边界
解决的核心思路是:不要按 char 截断,要按 Unicode 码点截断。
什么是Unicode码点?
**Unicode 码点(Unicode Code Point)**是 Unicode 编码体系中为每一个字符分配的唯一编号。
🔹 通俗理解:
你可以把 码点 看成是字符在 Unicode 字典中的“编号”。
- 每个字符,无论是英文、中文、表情符号,还是控制字符,在 Unicode 中都有一个编号(码点)。
- 码点用十六进制书写,通常格式是:
U+XXXX(例如:U+0041表示大写字母A)。
🔹 示例:
字符 Unicode 码点 描述 A U+0041 英文字母 A 中 U+4E2D 汉字 “中” 😀 U+1F600 Emoji 表情(高位字符) 空格 U+0020 普通空格字符
🔹 码点 vs 字符 vs char:
概念 含义 字符 屏幕上看到的 A、你、😀 等 码点 该字符在 Unicode 中的编号(U+XXXX) char Java 中的 16 位数据单位,能表示 U+0000 到 U+FFFF 的字符。超过范围(如 😀)需用两个 char 表示(即代理对)
🔹 为什么要关注码点?
因为:
- Java 中
String.length()返回的是 char 的个数,并不是字符个数;substring等操作基于char,可能会截断一个码点的一部分(即代理对中间);- 使用
codePointCount()、offsetByCodePoints()可以避免截断问题,确保按“完整字符”操作。
如需按 “字符”维度 正确处理字符串(特别是带 Emoji 的),就要使用“码点”相关 API,而不是单纯的
char。
4.1 安全的截断方法
public static String substringByCodePoint(String input, int codePointLength) {
if (input == null || codePointLength <= 0) return "";
int endOffset = input.offsetByCodePoints(0, Math.min(codePointLength, input.codePointCount(0, input.length())));
return input.substring(0, endOffset);
}
该方法使用 offsetByCodePoints 来获取“第 N 个 Unicode 字符”的结束位置,确保不会截断代理对。
4.2 正确的 MongoDB 写入流程
String safeText = substringByCodePoint(originalText, 150);
mongoCollection.insertOne(new Document("text", safeText));
五、总结与建议
| 问题点 | 原因描述 | 正确做法 |
|---|---|---|
| MongoDB 写入失败 | 字符串中含非法 UTF-8 | 避免截断代理对,使用码点截断 |
| substring 按 char 截断 | 无法处理 Emoji 等代理对字符 | 使用 offsetByCodePoints 截断 |
| Emoji、特殊符号保存异常 | 被截成半个字符,转码后变成非法 UTF-8 字节流 | 保持 Unicode 字符完整 |
🧠 技术提醒
很多开发者在做字符串摘要、截断评论、截断简介时,习惯性使用 substring(x, y),但一旦内容包含 Emoji 或其他代理字符,这种做法就会“暗藏杀机”。
特别是在写入数据库或网络传输场景,务必考虑 字符串编码的完整性。这类 bug 不仅难以发现,还容易被误判为“数据库有问题”或“编码不支持”。
✅ 建议结论:
凡涉及 Emoji 的文本截断,一律使用码点方式处理!
如果你也遇到过类似问题,不妨检查下你的 substring,看看是不是也“截断了一个流汗黄豆😅”。



评论区