




文章摘要(AI生成)
短链接系统是系统设计类面试中的热门考题,它表面上看似简单,实际上涉及多个关键设计要点,包括唯一性、存储、性能、高可用性等。短链接广泛应用于社交平台、营销推广和数据统计等场景,面试官通过此题考察候选人的系统设计思路及对存储扩展、性能优化和可靠性的理解。 核心设计目标包括将长链接转换为短链接、跳转功能、访问统计及短链接的失效机制。主要难点在于如何保障短链唯一性、支持水平扩展、高可用性设计以及性能优化。设计思路包括短链生成策略(如自增ID、哈希、雪花算法)、存储方案(关系型数据库或NoSQL)、架构流程设计等。 系统架构设计需考虑高性能优化、高可用性、监控和日志收集等方面,并结合缓存策略和分布式生成来应对高并发访问。总结时强调了代价最小与最大策略,展示了应对安全问题和扩展功能的思路,如用户自定义短链和短链过期机制等。
一、引言
在系统设计类面试中,短链接系统几乎是最常见的考题之一。原因在于它表面上看似简单:将一个长长的 URL 转换为简短的字符串,但背后却涉及 唯一性、存储、性能、扩展性、高可用 等多个核心设计点。
二、场景介绍
在实际业务中,短链接被广泛应用于:
- 社交平台:微博、推特、微信分享中,短链便于展示与传播
- 营销推广:短信、广告活动中,短链节省空间并可追踪效果
- 数据统计:短链可收集点击量、来源、用户画像等数据
因此,面试官通过该题,不仅考察候选人的 系统设计思路,更会关注其对 存储扩展、性能优化与可靠性保障 的理解。
三、核心设计目标
一个短链接系统要包含如下功能:
- 长链接 → 短链接:将请求长连接转换为短链接
- 短链接 → 原始链接:用户请求短链接时可以跳转到原始链接
- 链接访问统计(可选):短链接访问量可统计,方便流量分析和控制
- 链接过期/失效机制(可选):对过期短链进行及时回收,节约资源
四、常见问题和难点
在短链接系统中,主要难点有:
- 唯一性保障:在分布式场景下如何避免短链冲突。
- 水平扩展:当存储和访问量到达数十亿级别时,如何保证系统可水平扩展。
- 高可用设计:如何实现多机房容灾、主从复制,避免单点故障。
- 性能优化:在高并发访问下,如何用缓存、预生成短链池、Bloom Filter 来减少数据库压力。
- 统计与分析:既要能实时统计,又不能影响主流程的性能(一般用异步 + 批量处理)。
- 安全与风控:需要引入黑名单、内容检测和风控策略,防止系统被滥用。
五、核心设计思路
在面试中,面试官通常希望考察你对 短链生成策略、存储方案、系统流程和扩展能力 的理解。因此核心设计思路可以从以下几个维度展开:
1. 短链生成策略
- 自增 ID + 进制转换
- 优点:实现简单、生成速度快
- 缺点:可预测性强,单机容易扩展受限
- 面试常问点:可否分布式生成?如何避免冲突?
- 哈希 + 冲突检测(如 MD5/SHA)
- 优点:短链长度可控,分布式生成容易
- 缺点:可能出现冲突,需要额外检测和重试
- 面试常问点:冲突概率如何控制?性能损耗如何优化?
- 雪花算法 + 64进制编码
- 优点:分布式唯一、生成有序、支持高并发
- 安全性比自增 ID 高,可加随机后缀防止预测
- 面试常问点:如何保证不同节点生成 ID 不重复?
💡 面试技巧:先提代价最小策略,再说明弊端,最后给分布式或雪花算法优化方案。
2. 存储方案
- 关系型数据库(MySQL)
- 适合中小规模,水平分库分表扩展
- 面试常问点:如何分库分表?路由策略怎么设计?
- NoSQL / KV 存储(Redis、Cassandra)
- 支持海量短链,高并发读写
- 面试常问点:如何保证一致性?如何水平扩展?
💡 面试技巧:说明缓存 + 数据库组合,展示你对性能和可扩展性的理解。
3. 架构流程设计
- API 层:生成短链、解析短链、统计访问
- 服务层:
- 短链生成服务:负责生成唯一短链并写入存储
- 跳转服务:负责短链解析并重定向
- 统计服务:异步收集访问数据,避免阻塞
- 存储层:
- 数据库 + 缓存
- 本地或全局 Bloom Filter 防止缓存穿透
- 批量预生成短链池,提升生成效率
面试常问点:请求流转图怎么画?缓存穿透如何防护?高并发情况下如何保证性能?
四、系统架构设计
1. 整体架构
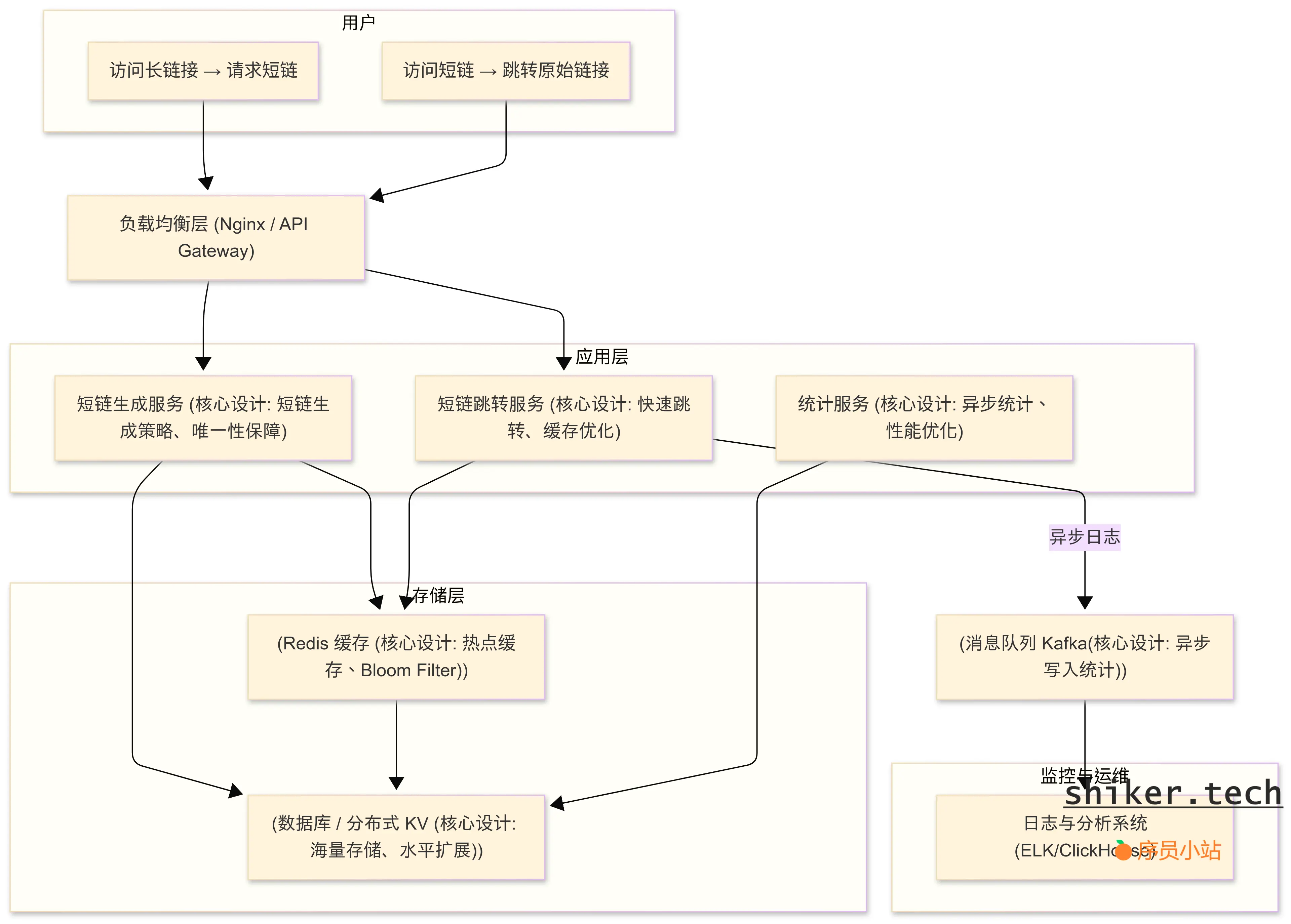
- 请求层
- 用户请求先经过 负载均衡(Nginx / API Gateway)
- 作用:分发流量、做基础限流、提升可用性
- 应用层
- 短链生成服务:生成短链,写入存储
- 跳转服务:解析短链并重定向
- 统计服务:异步收集访问日志,不阻塞跳转
- 存储层
- 数据库:存储短链映射和元信息
- 缓存:Redis 缓存短链映射,加速访问
- 辅助组件:Bloom Filter 防止缓存穿透
面试常问点:请求如何流转?缓存穿透怎么防?如何设计异步统计流程?
2. 高性能优化
- 缓存策略:
- Redis 存储热门短链
- 批量预生成短链池,提高生成效率
- 本地 Bloom Filter:减少对数据库的无效访问
- CDN 加速(可选):热点短链分发,降低中心节点压力
面试常问点:如何快速跳转?如何减少 DB 压力?缓存和数据库如何协同工作?
3. 高可用与扩展
- 数据分片 & 水平扩展
- 支持亿级短链存储
- 主从复制 + 多机房部署
- 保证容灾和高可用
- 短链唯一性保障
- 分布式生成(雪花算法)或集中 ID 分配
- 保证多节点并发生成不冲突
面试常问点:如何保证高可用?分布式 ID 如何避免冲突?数据库如何水平扩展?
4. 日志与监控
- 日志收集:访问日志写入 Kafka 或异步队列
- 监控:统计短链访问量、系统健康状态
- 告警:短链生成异常、跳转失败、缓存穿透等
面试常问点:如何做访问统计而不影响性能?如何快速发现系统问题?
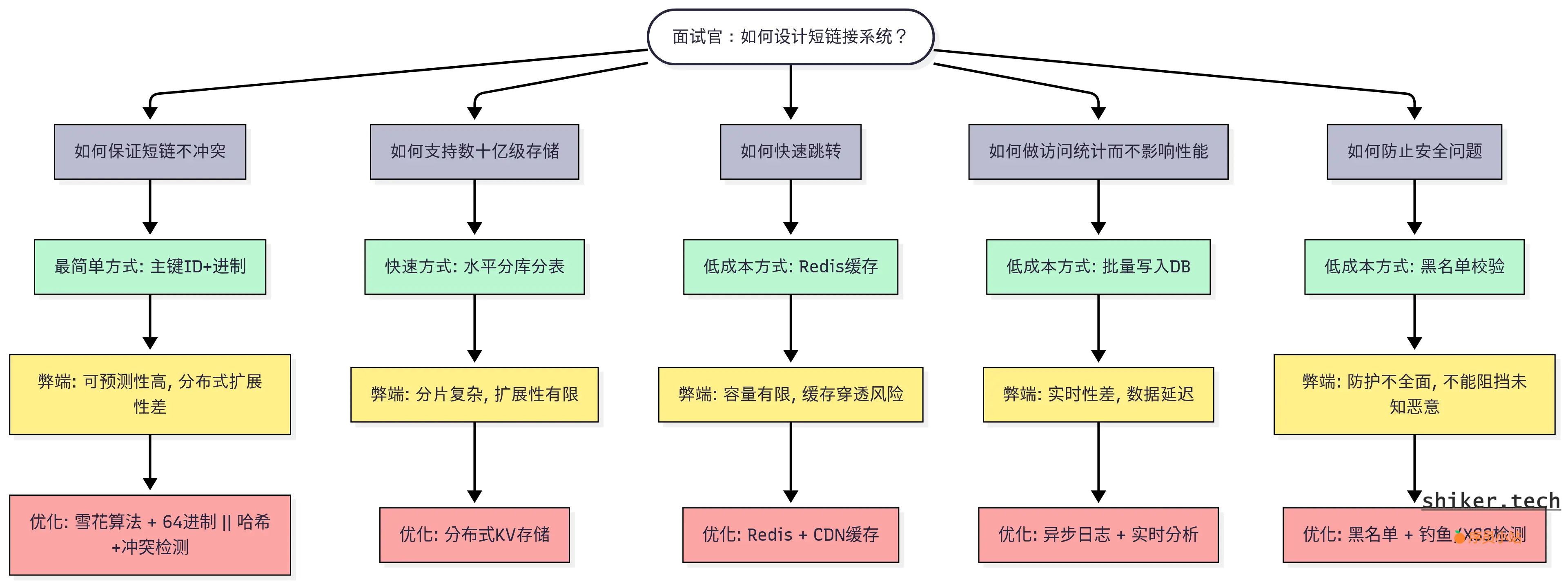
五、关键问题解析
| 核心问题 | 实施原因 | 代价最小策略(快速上线、低成本) | 代价最大策略(健壮、可扩展、高成本) |
|---|---|---|---|
| 如何保证短链不冲突 | 确保每个短链唯一,避免跳转错误 | 自增 ID + 进制转换(实现简单,生成快) | 哈希 + 冲突检测(复杂,需处理冲突) |
| 如何支持数十亿级存储 | 支撑海量短链存储,保证查询性能 | 水平分库分表(传统数据库扩展,成本中等) | 分布式 KV 存储(Cassandra/DynamoDB,高性能,运维复杂) |
| 如何快速跳转 | 短链访问量大,保证用户体验 | Redis 缓存短链映射(快速,易部署) | CDN 缓存热点链接(高性能,但依赖额外基础设施) |
| 如何做访问统计而不影响性能 | 点击量统计不影响跳转性能 | 定时批量写入数据库(简单,适合中低访问量) | 异步日志上报(Kafka + ELK,复杂,支持高并发) |
| 如何防止安全问题 | 防止恶意链接、钓鱼、XSS | URL 黑名单校验(实现成本低,快速上线) | 防止恶意钓鱼 / XSS(复杂检测逻辑,开发成本高) |
总结分析:
- 代价最小的策略:
- 短链生成:自增 ID,安全性弱
- 存储扩展:水平分库分表
- 快速跳转:Redis 缓存
- 访问统计:定时批量写入
- 安全防护:黑名单校验
- 代价最大的策略:
- 短链生成:哈希 + 冲突检测,也可以折中,使用雪花算法+进制转换
- 存储扩展:分布式 KV 存储
- 快速跳转:CDN 缓存
- 访问统计:异步日志(Kafka + ELK)
- 安全防护:防恶意钓鱼/XSS
面试技巧
- 描述架构时,建议按 请求层 → 应用层 → 存储层 → 辅助组件 顺序讲
- 对关键点进行优化说明:缓存、Bloom Filter、异步统计、分布式生成
- 遇追问,展示高可用和分布式扩展方案,体现系统思维和架构深度
六、扩展功能(加分点)
| 扩展功能 | 功能描述 | 实现思路 | 面试常问点 |
|---|---|---|---|
| 用户自定义短链 | 允许用户指定短链别名(如 t.cn/spring2025) |
校验唯一性、限制长度和字符集、避免与系统短链冲突 | 如何与分布式生成短链共存?冲突处理逻辑如何设计? |
| 短链过期 / 动态失效 | 短链可设置过期时间或在特定条件下失效 | 数据库增加 expire_time 字段,跳转服务判断是否过期,缓存 TTL 提速 |
高并发下如何高效判断短链是否过期?如何批量清理过期短链? |
| 访问统计与数据分析 | 统计点击量、来源渠道、地域分布等 | 异步日志上报(Kafka/队列)、批量写入分析数据库(ClickHouse/ELK)、实时或延迟报表 | 如何统计点击而不影响跳转性能?实时分析如何设计? |
| 黑名单 & 风控系统 | 防止恶意短链(钓鱼、XSS、违规内容) | URL 黑名单校验,风控规则:异常访问检测、频率限制,可接入第三方安全服务 | 高并发下安全检测如何设计?风控策略如何灵活可扩展? |
七、总结与面试答题套路
答这种题时,不要一上来就给架构图,而是要有条理:
- 明确需求 → 功能性 + 非功能性
- 列出核心功能实现 → 代价最小方案
- 分析弊端 / 风险 → 展示对问题的理解
- 提出优化方案 → 分布式、高可用、高性能
- 描述架构流程 → 请求流转、缓存、存储、统计
- 可选扩展功能 → 用户自定义短链、短链过期、风控、访问分析
💡 面试技巧:
- 用 代价最小 → 弊端 → 优化方案 模式讲解,逻辑清晰
- 必要时结合简图,辅助口述
- 面试官追问时,深入性能、安全、扩展性细节



评论区