




文章摘要(AI生成)
索引在数据库中起到了提高数据检索效率和降低IO成本的作用。不同的数据结构实现索引有各自的优缺点,如Hash表适用于等值查询但不支持范围查询,而B+树在等值查询和范围查询方面效果均较好。在MySQL中,不同引擎的索引实现也有所区别,如InnoDB引擎使用B+树构建聚簇索引,而MyISAM引擎的主键索引和辅助索引结构相同。为了避免回表查询,可以创建覆盖索引,提高命中率。建立索引的原则包括频繁出现在where条件、order by、group by语句中的字段以及需要频繁查询的列等。需要注意的是,索引的建立要考虑字段的区分度和长度,避免过多的索引导致更新和插入变慢。综上所述,合理使用不同数据结构和引擎的索引实现,并按照建立索引的原则进行优化,可以有效提升数据库的查询效率。
索引优势:提高数据检索效率降低数据库IO成本;通过索引对数据排序,降低数据排序成本。
索引劣势:占据磁盘空间;降低表的查询效率
什么数据结构实现索引?
我们假设有一组数据【1,2,5,9,12,13,15,16,23,23,44】,分别需要查找数据中1和大于1小于10的数据项。
Hash表:等值查询为O(1),范围查询为O(n)。只适用于等值查询,不支持范围查找;

平衡二叉查找树:等值查询为O(log2N),范围查询为O(log2N)。树越高,遍历次数越多(1-4次),且范围查找时需要多次遍历(最小值的右子树,最大值的左子树,遍历次数X2),效率不高;

B树:降低了树的高度,遍历次数减少(3次),但范围查找仍需要多次遍历。
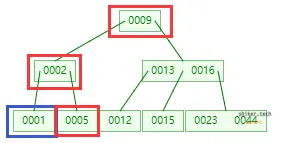
B+树:B树的改进,只有叶子节点才会存储数据。叶子节点通过双向指针连接,方便了等值查询和范围查询(遍历次数均为3)。
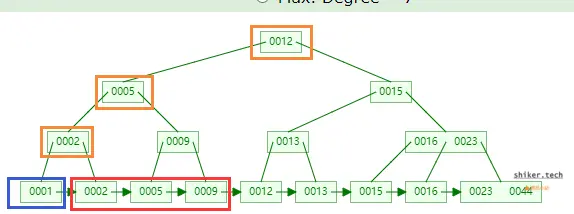
由上示例可见,在等值查询和范围查询的遍历中从查询效率和树的遍历次数来看,B+树在范围查询和等值查询中支持效果最好。所以使用B+树作为索引的数据结构最为合理。
不同引擎的索引实现
在MySQL架构介绍一文中,我们知道InnoDB引擎主要为ibd文件存储表数据和索引信息,而MyISAM引擎则是分别用myd文件存放表数据信息,和myi文件存放索引信息。
MyISAM索引
MyISAM的数据文件和索引文件是分开存储的。MyISAM使用B+树构建索引树时,叶子节点中存储的键值为索引列的值,数据为索引所在行的磁盘地址。
主键索引和辅助索引的结构相同,没有任何区别,叶子节点的数据存储的都是行记 录的磁盘地址。只是主键索引的键值是唯一的,而辅助索引的键值可以重复。
以主键索引为例,示意如下:

InnoDB索引
每个InnoDB表都有一个聚簇索引 ,聚簇索引使用B+树构建,叶子节点存储的数据是整行记录。一般情况下,聚簇索引等同于主键索引,当一个表没有创建主键索引时,会选择第一个不为null的唯一索引作为聚簇索引,主键与唯一索引都不存在时,InnoDB会自动创建一个ROWID字段来构建聚簇索引。除聚簇索引之外的所有索引都称为辅助索引。
主键索引:主键索引的叶子节点会存储数据行,辅助索引只会存储主键值。示例如下:

辅助索引:除聚簇索引之外的所有索引都称为辅助索引,InnoDB的辅助索引只会存储主键值而非磁盘地址。使用辅助索引需要检索两遍索引:首先检索辅助索引获得主键,然后使用主键到主索引中检索获得记录。查询示意如下:

其中,根据在辅助索引树中获取的主键id,到主键索引树检索数据的过程称为回表查询。
组合索引:例如我们创建了一个联合索引idx_abc(a,b,c),索引树如下所示,则索引树中节点中的索引项按照(a,b,c)的顺序从大到小排列,先按照a列排序,a列相同时按照b列排序,b列相同按照c列排序。在最地城的叶子节点中,如果两个索引项的a,b,c三列都相同,索引项按照主键id排序。

由于组合索引的这种创建规则,所以我们在查找时需要遵循最左前缀匹配规则:使用组合索引查询时,mysql会一直向右匹配直至遇到范围查询(>、<、 between、like)就停止匹配。
组合索引创建原则
- 频繁出现在where条件中的列,建议创建组合索引。
- 频繁出现在order by和group by语句中的列,建议按照顺序去创建组合索引。
order by a,b需要组合索引列顺序(a,b)。如果索引的顺序是(b,a),是用不到索引的。- 常出现在select语句中的列,也建议创建组合索引。
InnoDB如何避免回表?
当我们使用辅助索引查询数据记录时,需要由辅助索引找到主键,再由主键找到对应的数据记录。如果我们的查询语句使用的是select * 获取数据结果的场景,则不可避免的需要回表查询相应数据记录。而如果我们要获取的列刚好在我们的辅助索引上,那么就避免了再次根据主键查询主键索引获取记录的过程,那么我们就称我们创建的辅助索引为覆盖索引。
组合索引如何提高命中?
可以开启索引条件下推。不使用索引条件下推时,不满足最左前缀的索引条件的比较是在存储引擎层进行的,非索引条件的比较是在Server 层进行的。 使用索引条件下推,所有的索引条件的比较是在存储引擎层进行的,非索引条件的比较是在Server层进行的。
创建索引的原则
哪些条件下要建立索引?
- 频繁出现在where 条件判断,order排序,group by分组字段
- select 频繁查询的列,考虑是否需要创建联合索引(覆盖索引,不回表)
- 多表join关联查询,on字段两边的字段都要创建索引
索引优化的相关tip
- 表记录很少不需创建索引
- 一个表的索引个数不能过多,否则更新和插入变慢
- 频繁更新的字段不建议作为索引
- 区分度低的字段不建议作为索引
- InnoDB的主键索引最好使用长整型,主键索引树一个页节点时16K,字段越长可存储数据越少,区间查询时会使IO次数增多。
- 不建议使用无序的值作为索引
- 尽量创建组合索引,而不是单列索引



评论区