




文章摘要(AI生成)
这篇文章主要讨论了在老项目技术优化过程中,数据层常见的几个难题:阅读难、拆表难等。作者提出,应该避免过多的关联查询,而是赋予各个领域对象查询能力。同时,需要注意聚合函数的使用,应该将统计能力赋予给领域对象而非数据库。文章还介绍了两种方案来解决大数据量的统计问题:一是建立统计表进行定时落地,二是利用nosql技术进行实时统计。最后,作者指出在面对大数据时,即使对分组条件加索引也难以实现满意的优化效果,建议使用统计表和nosql技术来优化数据处理性能。文章强调了保持面向对象的编程思维对于应对数据层技术优化的重要性。
最近在做一些老项目的技术优化,众所周知,老项目在数据层一般有好几个老大难:
- 阅读难:写的时候天马行空,时不时的用自己卓越的sql能力,写几个关联了n张表的大sql。a关联b,b关联c都是小菜,最后给你来个union让你不得不服~
- 拆表难:想做分表?nonono,你以为我之前不想分表?我这张表什么查询都有,group,max,having你能想到的聚合函数我全用,你想不到的我还有text等着你!
这几个老大难无疑暴露出很多新人在写代码时的很多“恶习”,下面我们就这上面的两个大难来思考一下:
- 关联查询是否必要?-我们应该面向什么编程
- 聚合函数如何替代?-计算应该交由谁来承担
如果你是一个数据库研发人员,请跳过此篇文章。如果你是一个后端研发,那么看完本文后,你应该重新审视下自己的编码习惯
关联查询是否必要?
作为后端研发,我们通常做的只有两类编程,要么是面向过程的编程,要么是面向对象的编程,但一定不是面向数据库的编程。数据库只是一个存储工具,用来帮助我们完成过程持久化或者对象持久化的。
比如,你在淘宝下了一个订单买了一件衣服。如果你是面向对象的编程开发人员,那么你会把【你】【订单】【衣服】作为买衣服这一件事情的三个实体。这三个实体对应了【顾客】【订单】【商品】这三个领域对象。在程序中我们会在【顾客】中定义【下订单】和【买商品】两个操作,然后将【下订单】和【买商品】这两个操作的具体实现分别交给他们各自所属的领域对象【订单】和【商品】中。
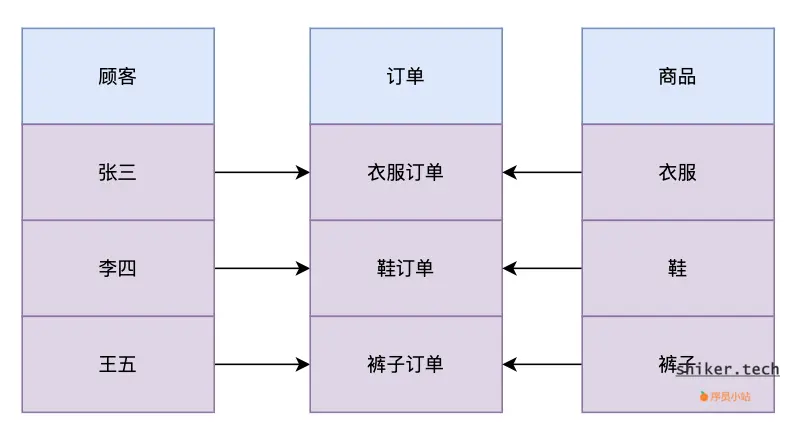
好了,到此为止我们已经实现了顾客下订单买商品的操作。当然,为了方便我们对事件进行追溯,我们把每次操作都进行持久化存储,把他们都存储到了数据库中:
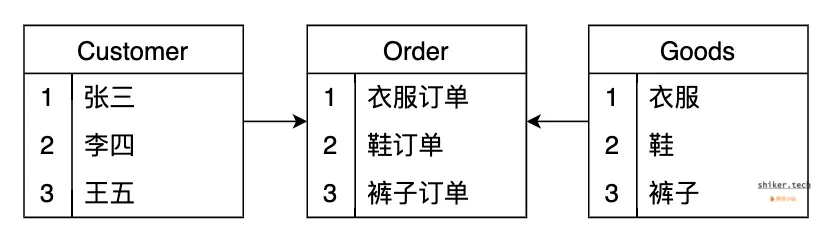
现在问题来了,我们想要查询张三一共买了多少件衣服?
这个问题的解法很简单,通过订单表关联顾客表,商品表,用顾客筛选一下就OK:
SELECT
count( 1 )
FROM
`order` o,
customer c,
goods g
WHERE
o.goods_id = g.id
AND o.customer_id = c.id
AND c.user_name = '张三'
AND g.name = '衣服';
行了,如果用这个出招,那基本上是玩完了。等你以后想把服务进行扩展,对顾客和商品、订单分别用三个服务管理的时候,你就会发现:无语了家人们,这谁写的这大sql啊(然后一看git,霍,竟然是自己~~)
那么如果我们面向对象,这个问题该如何解决呢?
首先我们这个查询分为三步:
- 查询姓名为【张三】的顾客
- 查询商品-【衣服】
- 查询订单中为【张三】下的【衣服】相关的订单信息
所以我们其实可以这么设计:

那么在已有的领域中,我们进行了功能拓展。即对【顾客】【订单】【商品】这三个领域分别进行了功能增强。在后续我们想要对顾客和商品、订单分别用三个服务管理的时候,我们忽然发现,由一个服务拆分到其他子服务只是进行了模块拆解,并没有有类似拆分sql,功能细化这些琐事。可见,时刻保持面向对象的思维是很重要的,如果我们写了关联查询而不是赋予各个领域查询能力,那么在后续的工作中,我们既要构建查询能力,又要拆分大sql。
聚合函数如何替代?
在上面我们讲了,要赋予领域对象能力,而不是通过关联的大sql替代我们原本的对象操作。那么理所当然的,聚合函数所拥有的统计能力也应该被我们的领域对象持有,而不是数据库和数据表。我们在实现一些功能的时候,往往说不要重复造轮子,要借助现有能力,但是在这里又要说不要借助数据库提供的统计能力,这是为什么呢?
这里我们要搞清楚一个问题:我们用数据库,特指的关系性数据库,着重使用了他的一个独有的特色:强有力的数据一致性保证。如果要将统计分析能力交给数据库,那么数据库集群就帮助服务做了很多计算操作,如果我们对千万级数据进行求和,或者对亿级数据进行分组topN操作,那么交给数据库来做肯定是不合适的,我们需要考虑两种方案:
- 提前预算,定时落地:建立统计表,按日、小时进行统计,然后设计定时任务进行及时归并处理,这方面可以借助大数据的能力进行实现
- 实时计算,数据会写:借助nosql能力,实时对数据进行统计分析,例如使用redis完成用户量和商品购买的topN统计等。通过关系性数据库进行统计数据的冷备
例如,我们要统计,所有所有顾客每个月的月度账单是多少?
使用sql查询如下:
SELECT
g.name,
sum( o.amount )
FROM
`order` o,
customer c
WHERE
o.goods_id = g.id
AND o.customer_id = c.id
GROUP BY c.user_name;
这个sql可以说是又关联又聚合,这在拆分的时候可以说是难上加难。我们首先需要将sql拆小,同关联拆分一样,最后我们拆解只剩下了对订单表的金额按顾客id分组对金额求和。
SELECT
o.goods_id,
sum( o.amount )
FROM
`order` o
GROUP BY o.customer_id;
拆分到这里我们只剩一个分组聚合了,如果数据量较小,那么到这里就可以戛然而止了。但是如果数据量过大,我们就会发现,一个小小的聚合sql竟然也会耗时几秒,甚至几十秒!!这种庞大的数据量,就导致我们即使对分组条件加上了索引,还远远不能达到一个满意的优化效果。
这个时候该怎么办呢?我们应该考虑使用我们上述的两种方案,假如我们选择方案二,我们先统计存量数据的各商品名称之和,然后以【顾客-商品】为key,金额为value放入到redis中,然后待顾客每次写入数据时都对我们redis中存储的数据结果进行维护。在到达月底时我们再将数据写入到统计表中,这样每次月度账单只依赖我们统计表的每条月度统计数据。并不会对数据库的性能造成影响。



评论区