




文章摘要(AI生成)
总结:回溯法是一种搜索尝试过程,主要用于在搜索过程中寻找问题的解,当条件不满足时会返回尝试别的路径,常用于解决复杂问题。回溯法的基本步骤包括确定问题的解空间、确定扩展搜索规则以及深度优先搜索解空间等。递归和非递归是两种实现回溯法的方法,通过探索每一步可选择使用左括号或右括号的方式,及时过滤无效解并确保生成一组有效结果。通过分析回溯法的框架和实现,可以更好地理解其工作原理和应用场景。回溯法可以灵活地解决括号生成等问题,为解决其他问题提供了一种通用解题方法。
回溯法
基本概念
回溯算法实际上一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就“回溯”返回,尝试别的路径。
回溯法是一种选优搜索法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为“回溯点”。
许多复杂的,规模较大的问题都可以使用回溯法,有“通用解题方法”的美称。
在包含问题的所有解的解空间树中,按照深度优先搜索的策略,从根结点出发深度探索解空间树。当探索到某一结点时,要先判断该结点是否包含问题的解,如果包含,就从该结点出发继续探索下去,如果该结点不包含问题的解,则逐层向其祖先结点回溯。(其实回溯法就是对隐式图的深度优先搜索算法)。
若用回溯法求问题的所有解时,要回溯到根,且根结点的所有可行的子树都要已被搜索遍才结束。
而若使用回溯法求任一个解时,只要搜索到问题的一个解就可以结束。
基本步骤
用回溯法解题的一般步骤:
(1)针对所给问题,确定问题的解空间:
首先应明确定义问题的解空间,问题的解空间应至少包含问题的一个(最优)解。
(2)确定结点的扩展搜索规则
(3)以深度优先方式搜索解空间,并在搜索过程中用剪枝函数避免无效搜索。
算法框架
(1)问题框架
设问题的解是一个n维向量(a1,a2,………,an),约束条件是ai(i=1,2,3,……,n)之间满足某种条件,记为f(ai)。
(2)非递归回溯框架
1: int a[n],i;
2: 初始化数组a[];
3: i = 1;
4: while (i>0(有路可走) and (未达到目标)) // 还未回溯到头
5: {
6: if(i > n) // 搜索到叶结点
7: {
8: 搜索到一个解,输出;
9: }
10: else // 处理第i个元素
11: {
12: a[i]第一个可能的值;
13: while(a[i]在不满足约束条件且在搜索空间内)
14: {
15: a[i]下一个可能的值;
16: }
17: if(a[i]在搜索空间内)
18: {
19: 标识占用的资源;
20: i = i+1; // 扩展下一个结点
21: }
22: else
23: {
24: 清理所占的状态空间; // 回溯
25: i = i –1;
26: }
27: }
(3)递归的算法框架
回溯法是对解空间的深度优先搜索,在一般情况下使用递归函数来实现回溯法比较简单,其中i为搜索的深度,框架如下:
1: int a[n];
2: try(int i)
3: {
4: if(i>n)
5: 输出结果;
6: else
7: {
8: for(j = 下界; j <= 上界; j=j+1) // 枚举i所有可能的路径
9: {
10: if(fun(j)) // 满足限界函数和约束条件
11: {
12: a[i] = j;
13: ... // 其他操作
14: try(i+1);
15: 回溯前的清理工作(如a[i]置空值等);
16: }
17: }
18: }
19: }
括号生成
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
示例 1:
输入:n = 3
输出:["((()))","(()())","(())()","()(())","()()()"]
示例 2:
输入:n = 1
输出:["()"]
提示:
1 <= n <= 8
SOLUTION:回溯法
1、每一步 可选择使用 左括号或右括号 添加到 当前组合末尾
2、及时过滤无效解: 要想保证最终有效组合 那么当前临时组合中 右括号出现的次数不能多于左括号(若有 则最后的生成的结果一定为无效组 此时需返回)
3、左、右括号刚好都使用完了 即生成一组有效结果
class Solution {
public List<String> generateParenthesis(int n) {
List<String> res = new LinkedList<>();
String[] choose = new String[]{"(", ")"};
backTrack(n, n, choose, new StringBuilder(), res);
return res;
}
/**
* remainLeftParenNums: 左括号剩余数量
* remainRightParenNums: 右括号剩余数量
* choose : 每次可做的选择 即 ( 或 )
* parenStr: 生成的临时组合
* res: 最终结果
*/
private void backTrack(int remainLeftParenNums, int remainRightParenNums, String[] choose, StringBuilder parenStr, List<String> res) {
// 迭代停止条件 左、右括号 刚好都用完了
if(remainLeftParenNums == 0 && remainRightParenNums == 0) {
res.add(new String(parenStr));
return;
}
// 剩余左括号的数量多 表明当前右括号出现的次数已多于左括号 此时已为无效组合
if(remainLeftParenNums > remainRightParenNums) {
return;
}
for(int i = 0; i < choose.length; ++i) {
String paren = choose[i];
parenStr.append(paren);
// 每次要么使用左括号 要么括号
if(paren.equals("(") && remainLeftParenNums > 0) {
backTrack(remainLeftParenNums - 1, remainRightParenNums, choose, parenStr, res);
} else if(paren.equals(")") && remainRightParenNums > 0) {
backTrack(remainLeftParenNums, remainRightParenNums - 1, choose, parenStr, res);
}
parenStr.deleteCharAt(parenStr.length() - 1);
}
}
}
全排列
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例 1:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
示例 2:
输入:nums = [0,1]
输出:[[0,1],[1,0]]
示例 3:
输入:nums = [1]
输出:[[1]]
SOLUTION:回溯法
class Solution {
public List<List<Integer>> permute(int[] nums) {
List<List<Integer>> res = new ArrayList<List<Integer>>();
List<Integer> output = new ArrayList<Integer>();
for (int num : nums) {
output.add(num);
}
int n = nums.length;
backtrack(n, output, res, 0);
return res;
}
public void backtrack(int n, List<Integer> output, List<List<Integer>> res, int first) {
// 所有数都填完了
if (first == n) {
res.add(new ArrayList<Integer>(output));
}
for (int i = first; i < n; i++) {
// 将output[i]填到未填数组的第一个位置
Collections.swap(output, first, i);
// 继续递归填下一个数
backtrack(n, output, res, first + 1);
// 递归一次后将数组还原,以便下次循环填写
Collections.swap(output, first, i);
}
}
}
组合总和
给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。
candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。
对于给定的输入,保证和为 target 的不同组合数少于 150 个。
示例 1:
输入:candidates = [2,3,6,7], target = 7
输出:[[2,2,3],[7]]
解释:
2 和 3 可以形成一组候选,2 + 2 + 3 = 7 。注意 2 可以使用多次。
7 也是一个候选, 7 = 7 。
仅有这两种组合。
示例 2:
输入: candidates = [2,3,5], target = 8
输出: [[2,2,2,2],[2,3,3],[3,5]]
示例 3:
输入: candidates = [2], target = 1
输出: []
SOLUTION: 回溯法
class Solution {
//最开始做的时候,按着前面的模板做的话会发现,会出现
//这种结果[[2, 2, 3], [2, 3, 2], [3, 2, 2], [7]],有重复的;
//为了保证没重复,就加一个表示当前遍历到的位置的变量indexNow
LinkedList<Integer> path = new LinkedList<Integer>();
List<List<Integer>> result = new LinkedList<>();
public List<List<Integer>> combinationSum(int[] candidates, int target) {
if (candidates.length == 0) {
return result;
}
//用正常的回溯的话是不会出现,提前结束循环的,但是如果出现那种,[2,3,4,5,6,1]的情况就会浪费很多无用功,
//所以有些就会现将candidates给排序一下;hadSum+candidates[i]>target就在这一层的for循环中break了
backTracking(candidates, target,0,0);
return result;
}
public void backTracking(int[] candidates,int target, int hadSum, int indexNow){
if (target == hadSum){
result.add(new ArrayList<>(path));
return;
}
if (target < hadSum ){
//剪枝了,但是还可以更短
return;
}
for (int i = indexNow; i < candidates.length; i++) {
//tmp可以理解成在当层和下一层是两个不同的变量,且保存值没关系;
path.add(candidates[i]);
//这里给下一层中的indexNow赋值就可以去从i本身开始,因为可以重复使用自己,但是为了避免重复,就舍弃<i的部分
backTracking(candidates, target, hadSum + candidates[i],i);
//撤销到上一步
path.removeLast();
}
}
}
贪心算法
基本概念
所谓贪心算法是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的仅是在某种意义上的局部最优解。
贪心算法没有固定的算法框架,算法设计的关键是贪心策略的选择。必须注意的是,贪心算法不是对所有问题都能得到整体最优解,选择的贪心策略必须具备无后效性,即某个状态以后的过程不会影响以前的状态,只与当前状态有关。
所以对所采用的贪心策略一定要仔细分析其是否满足无后效性。
贪心算法使用的前提是:局部最优策略能导致产生全局最优解。
使用场景
贪心策略适用的前提是:局部最优策略能导致产生全局最优解。
实际上,贪心算法适用的情况很少。一般,对一个问题分析是否适用于贪心算法,可以先选择该问题下的几个实际数据进行分析,就可做出判断。
基本步骤
从问题的某一初始解出发;
while (能朝给定总目标前进一步)
{
利用可行的决策,求出可行解的一个解元素;
}
由所有解元素组合成问题的一个可行解;
跳跃游戏
给定一个非负整数数组 nums ,你最初位于数组的 第一个下标 。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标。
示例 1:
输入:nums = [2,3,1,1,4]
输出:true
解释:可以先跳 1 步,从下标 0 到达下标 1, 然后再从下标 1 跳 3 步到达最后一个下标。
示例 2:
输入:nums = [3,2,1,0,4]
输出:false
解释:无论怎样,总会到达下标为 3 的位置。但该下标的最大跳跃长度是 0 , 所以永远不可能到达最后一个下标。
SOLUTION:贪心
我们可以用贪心的方法解决这个问题。
设想一下,对于数组中的任意一个位置 y,我们如何判断它是否可以到达?根据题目的描述,只要存在一个位置 x,它本身可以到达,并且它跳跃的最大长度为 x+nums[x],这个值大于等于 y,即 x+nums[x]≥y,那么位置 y 也可以到达。
换句话说,对于每一个可以到达的位置 x,它使得 x+1,x+2,⋯,x+nums[x] 这些连续的位置都可以到达。
这样以来,我们依次遍历数组中的每一个位置,并实时维护 最远可以到达的位置。对于当前遍历到的位置 x,如果它在 最远可以到达的位置 的范围内,那么我们就可以从起点通过若干次跳跃到达该位置,因此我们可以用 x+nums[x] 更新 最远可以到达的位置。
在遍历的过程中,如果 最远可以到达的位置 大于等于数组中的最后一个位置,那就说明最后一个位置可达,我们就可以直接返回 True 作为答案。反之,如果在遍历结束后,最后一个位置仍然不可达,我们就返回 False 作为答案。
public class Solution {
public boolean canJump(int[] nums) {
int n = nums.length;
int rightmost = 0;
for (int i = 0; i < n; ++i) {
if (i <= rightmost) {
rightmost = Math.max(rightmost, i + nums[i]);
if (rightmost >= n - 1) {
return true;
}
}
}
return false;
}
}
分支限界法
基本描述
类似于回溯法,也是一种在问题的解空间树T上搜索问题解的算法。但在一般情况下,分支限界法与回溯法的求解目标不同。回溯法的求解目标是找出T中满足约束条件的所有解,而分支限界法的求解目标则是找出满足约束条件的一个解,或是在满足约束条件的解中找出使某一目标函数值达到极大或极小的解,即在某种意义下的最优解。
所谓“分支”就是采用广度优先的策略,依次搜索E-结点的所有分支,也就是所有相邻结点,抛弃不满足约束条件的结点,其余结点加入活结点表。然后从表中选择一个结点作为下一个E-结点,继续搜索。
选择下一个E-结点的方式不同,则会有几种不同的分支搜索方式。
1)FIFO搜索
2)LIFO搜索
3)优先队列式搜索
基本步骤
由于求解目标不同,导致分支限界法与回溯法在解空间树T上的搜索方式也不相同。回溯法以深度优先的方式搜索解空间树T,而分支限界法则以广度优先或以最小耗费优先的方式搜索解空间树T。
分支限界法的搜索策略是:在扩展结点处,先生成其所有的儿子结点(分支),然后再从当前的活结点表中选择下一个扩展对点。为了有效地选择下一扩展结点,以加速搜索的进程,在每一活结点处,计算一个函数值(限界),并根据这些已计算出的函数值,从当前活结点表中选择一个最有利的结点作为扩展结点,使搜索朝着解空间树上有最优解的分支推进,以便尽快地找出一个最优解。
分支限界法常以广度优先或以最小耗费(最大效益)优先的方式搜索问题的解空间树。问题的解空间树是表示问题解空间的一棵有序树,常见的有子集树和排列树。在搜索问题的解空间树时,分支限界法与回溯法对当前扩展结点所使用的扩展方式不同。在分支限界法中,每一个活结点只有一次机会成为扩展结点。活结点一旦成为扩展结点,就一次性产生其所有儿子结点。在这些儿子结点中,那些导致不可行解或导致非最优解的儿子结点被舍弃,其余儿子结点被子加入活结点表中。此后,从活结点表中取下一结点成为当前扩展结点,并重复上述结点扩展过程。这个过程一直持续到找到所求的解或活结点表为空时为止。
其他
最长连续子序列
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1:
输入:nums = [100,4,200,1,3,2]
输出:4
解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
示例 2:
输入:nums = [0,3,7,2,5,8,4,6,0,1]
输出:9
SOLUTION
class Solution {
public int longestConsecutive(int[] nums) {
Set<Integer> num_set = new HashSet<Integer>();
for (int num : nums) {
num_set.add(num);
}
int longestStreak = 0;
for (int num : num_set) {
if (!num_set.contains(num - 1)) {
int currentNum = num;
int currentStreak = 1;
while (num_set.contains(currentNum + 1)) {
currentNum += 1;
currentStreak += 1;
}
longestStreak = Math.max(longestStreak, currentStreak);
}
}
return longestStreak;
}
}
整数反转
给你一个 32 位的有符号整数 x ,返回将 x 中的数字部分反转后的结果。
如果反转后整数超过 32 位的有符号整数的范围 [−231, 231 − 1] ,就返回 0。
假设环境不允许存储 64 位整数(有符号或无符号)。
示例 1:
输入:x = 123
输出:321
示例 2:
输入:x = -123
输出:-321
示例 3:
输入:x = 120
输出:21
示例 4:
输入:x = 0
输出:0
SOLUTION:数学
本题如果不考虑溢出问题,是非常简单的。解决溢出问题有两个思路,第一个思路是通过字符串转换加try catch的方式来解决,第二个思路就是通过数学计算来解决。
由于字符串转换的效率较低且使用较多库函数,所以解题方案不考虑该方法,而是通过数学计算来解决。
通过循环将数字x的每一位拆开,在计算新值时每一步都判断是否溢出。
溢出条件有两个,一个是大于整数最大值MAX_VALUE,另一个是小于整数最小值MIN_VALUE,设当前计算结果为ans,下一位为pop。
从ans * 10 + pop > MAX_VALUE这个溢出条件来看
- 当出现
ans > MAX_VALUE / 10且还有pop需要添加时,则一定溢出 - 当出现
ans == MAX_VALUE / 10且pop > 7时,则一定溢出,7是2^31 - 1的个位数
从ans * 10 + pop < MIN_VALUE这个溢出条件来看
- 当出现
ans < MIN_VALUE / 10且还有pop需要添加时,则一定溢出 - 当出现
ans == MIN_VALUE / 10且pop < -8时,则一定溢出,8是-2^31的个位数
class Solution {
public int reverse(int x) {
int ans = 0;
while (x != 0) {
int pop = x % 10;
if (ans > Integer.MAX_VALUE / 10 || (ans == Integer.MAX_VALUE / 10 && pop > 7))
return 0;
if (ans < Integer.MIN_VALUE / 10 || (ans == Integer.MIN_VALUE / 10 && pop < -8))
return 0;
ans = ans * 10 + pop;
x /= 10;
}
return ans;
}
}
无重复字符的最长子串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: s = "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: s = "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
示例 4:
输入: s = ""
输出: 0
SOLUTION:滑动窗口
我们不妨以示例一中的字符串abcabcbb 为例,找出从每一个字符开始的,不包含重复字符的最长子串,那么其中最长的那个字符串即为答案。对于示例一中的字符串,我们列举出这些结果,其中括号中表示选中的字符以及最长的字符串:
以(a)bcabcbb 开始的最长字符串为(abc)abcbb;
以a(b)cabcbb 开始的最长字符串为a(bca)bcbb;
以ab(c)abcbb 开始的最长字符串为ab(cab)cbb;
以abc(a)bcbb 开始的最长字符串为abc(abc)bb;
以abca(b)cbb 开始的最长字符串为abca(bc)bb;
以abcab(c)bb 开始的最长字符串为abcab(cb)b;
以abcabc(b)b 开始的最长字符串为abcabc(b)b;
以abcabcb(b) 开始的最长字符串为abcabcb(b)。
class Solution {
public int lengthOfLongestSubstring(String s) {
// 哈希集合,记录每个字符是否出现过
Set<Character> occ = new HashSet<Character>();
int n = s.length();
// 右指针,初始值为 -1,相当于我们在字符串的左边界的左侧,还没有开始移动
int rk = -1, ans = 0;
for (int i = 0; i < n; ++i) {
if (i != 0) {
// 左指针向右移动一格,移除一个字符
occ.remove(s.charAt(i - 1));
}
while (rk + 1 < n && !occ.contains(s.charAt(rk + 1))) {
// 不断地移动右指针
occ.add(s.charAt(rk + 1));
++rk;
}
// 第 i 到 rk 个字符是一个极长的无重复字符子串
ans = Math.max(ans, rk - i + 1);
}
return ans;
}
}
合并区间
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间。
示例 1:
输入:intervals = [[1,3],[2,6],[8,10],[15,18]]
输出:[[1,6],[8,10],[15,18]]
解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
示例 2:
输入:intervals = [[1,4],[4,5]]
输出:[[1,5]]
解释:区间 [1,4] 和 [4,5] 可被视为重叠区间。
SOLUTION
举例:[[1,3],[2,6],[8,10],[15,18]]
1、最开始start = 1和 end = 3
2、到[2,6],发现2(新的开始) < 3(上一个的结尾),证明这两个节点直接有重叠要合并,合并之后的结尾end = Math.max(3, 6) = 6。
3、到[8, 10],发现8(新的开始) > 6(上一个的结尾),说明这两个区间没有交集,此时要保存[start, end]即[1,6],这是前两个区间合并的结果。 保存之后,更新start = 8, end = 10;
4、到[15, 18], 发现15 > 10, 说明这两个区间没有交集,要保存[start,end]即[8,10],这是上一个不重叠的区间。然后更新start = 15, end = 18。
5、遍历结束,保存当前的[start,end],这是最后一个区间
public int[][] merge(int[][] intervals) {
Arrays.sort(intervals, Comparator.comparingInt(n -> n[0]));
List<int[]> result = new ArrayList<>();
int lIndex = -1; int rIndex = -1;
for (int[] interval : intervals) {
if (lIndex < 0) {
lIndex = interval[0];
rIndex = interval[1];
} else if (interval[0] <= rIndex && interval[1] > rIndex) {
rIndex = interval[1];
} else if (interval[0] > rIndex) {
result.add(new int[]{lIndex, rIndex});
lIndex = interval[0];
rIndex = interval[1];
}
}
result.add(new int[]{lIndex, rIndex});
int[][] a = new int[result.size()][2];
for(int i = 0; i< result.size(); i++){
a[i] = result.get(i);
}
return a;
}
翻转二叉树
给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。
示例 1:
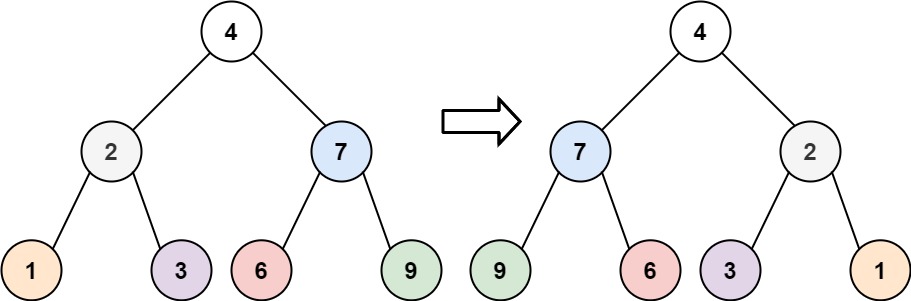
输入:root = [4,2,7,1,3,6,9]
输出:[4,7,2,9,6,3,1]
示例 2:
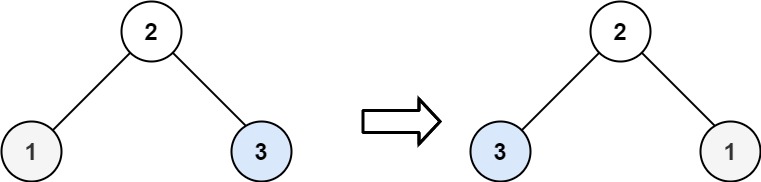
输入:root = [2,1,3]
输出:[2,3,1]
示例 3:
输入:root = []
输出:[]
SOLUTION: 递归
class Solution {
public TreeNode invertTree(TreeNode root) {
if (root == null) {
return null;
}
TreeNode left = invertTree(root.left);
TreeNode right = invertTree(root.right);
root.left = right;
root.right = left;
return root;
}
}



评论区