




文章摘要(AI生成)
本文介绍了分布式哈希算法在分布式系统中的重要性和应用。其中详细介绍了哈希取模和一致性哈希这两种具有代表性的分布式哈希算法,包括其工作原理、数据映射公式和数据调整比例等内容。通过比较可以发现,一致性哈希在节点动态增减时的数据调整效果更佳,数据迁移量更小。最后还介绍了哈希取模算法的简洁实现方式。深入理解这些理论知识,并将其应用到实际场景中,是关键所在。
在当今数字化的时代,分布式系统无处不在,支撑着海量数据的存储与处理。而在分布式系统的底层架构中,哈希算法宛如一位幕后英雄,默默掌控着数据的流向与分布。
分布式哈希算法的产生是为了解决分布式系统中数据存储和查找的效率问题,特别是在节点动态变化的情况下。其核心目标是通过均衡数据分布、减少数据迁移、提高查找效率和支持动态扩展,满足大规模系统的需求,广泛应用于分布式存储、P2P网络和负载均衡等场景。
今天,就让我们一同深入了解其中两种极具代表性的哈希算法 —— 哈希取模与一致性哈希。
概念介绍
哈希取模
哈希取模(Hash Modulo),堪称一种简洁明了的分布式哈希算法。其核心原理便是借助哈希函数算出键的哈希值,即 hash(key),接着将该哈希值对节点数量取模,也就是 hash(key) % N,如此一来,所得结果便是数据应存放的节点编号,最终数据就稳稳地存储在对应编号的节点上。为了让大家更直观地理解,特意准备了如下图示:
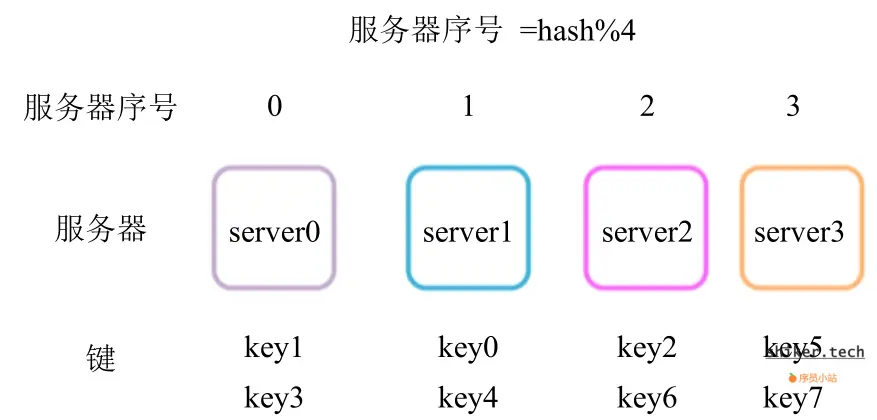
一致性哈希
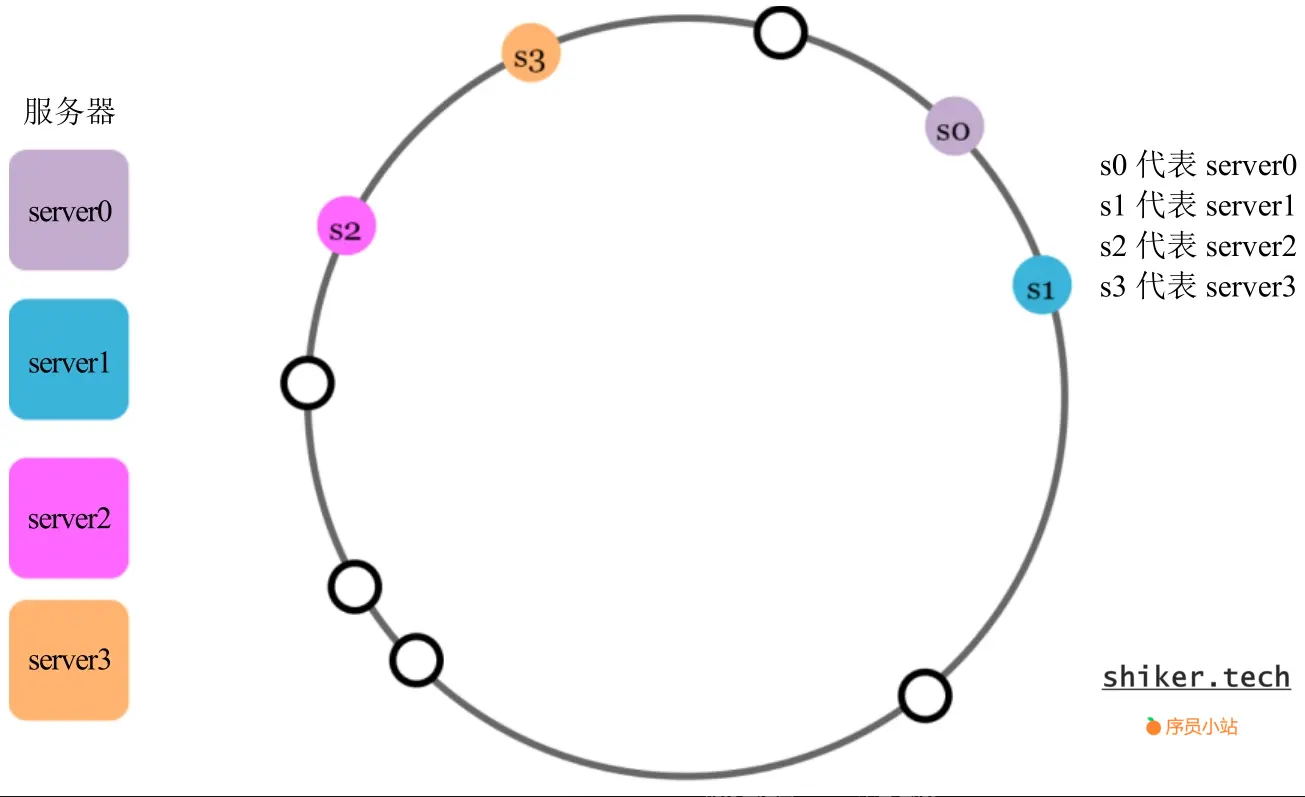
一致性哈希(Consistent Hashing)在分布式系统领域也是声名远扬,它主要致力于攻克节点动态增减时对哈希分布造成较大冲击的难题,在分布式缓存、分布式存储系统等场景中频繁现身。
其运作原理稍显复杂却精妙无比:
首先,构建一个哈希环,将整个哈希空间(例如,0 到 2^32-1)想象成一个逻辑上的闭环。
随后,运用哈希函数把每个节点精准映射到哈希环上的某一点。
再者,对于每个数据(键值)同样通过哈希函数投射到哈希环,之后沿着顺时针方向寻觅距离最近的节点,将数据安置于此。
不仅如此,考虑到节点分布可能失衡的状况,还引入了虚拟节点的概念,即为每个物理节点通过不同的哈希计算方式生成多个虚拟节点,从而促使数据分布更加均衡。下面这张图能助您快速领会:
数据Rehash
我们假如节点数量时n,添加虚拟节点后为p*n,总数据量为m,哈希函数为f(x)
节点增加
哈希取模
数据映射公式(节点数量从n变为n + q)
原始节点编号为
当节点数量变为n + q后,新的节点编号为
比例调整公式(节点数量从n变为n + q)
在下列数据范围内
相同元素的个数为
不同元素个数为:
所以要调整的数据比例公式为:
一致性哈希
数据映射公式(节点数量从n变为n + q)
数据x原本存储在节点Ni,其中H(Ni)是离H(x)顺时针方向最近的节点位置。当添加q个节点后,这些新节点在哈希环上有对应的位置
数据x会重新映射到离它顺时针方向最近的节点,可能是原来的节点或者新添加的节点。
比例调整公式(节点数量从n变为n + q)
对于一致性哈希,数据迁移比例相对比较复杂。假设哈希环上节点分布比较均匀,添加q个节点后,理论上每个节点负责的区间长度会从
变为
数据迁移比例p的一个近似计算公式(假设数据在哈希环上也是均匀分布的)为
节点减少
哈希取模
数据映射公式(节点数量从n变为n - q)
当节点数量从n变为n - q(q < n)时,新的节点编号为
比例调整公式(节点数量从n变为n - q)
在两者最小公倍数的数据范围内
相同元素的个数为
不同元素个数为:
所以要调整的数据比例公式为:
一致性哈希
数据映射公式(节点数量从n变为n - q)
当节点数量从n变为n - q(q < n)时,节点
在哈希环上位置不变,仍为
数据x原本存储在节点N(i),现在会重新映射到离H(x)顺时针方向最近的剩余节点。
比例调整公式(节点数量从n变为n - q)
理论上每个节点负责的区间长度会从
变为
数据迁移比例p的一个近似计算公式(假设数据在哈希环上也是均匀分布的)为
小结
综合来看,无论节点是增加还是减少,一致性哈希在数据调整方面的优势尽显,它所引发的数据迁移量往往是最小的。
具体而言,节点增加时,唯有新增节点数量恰好是原始节点整数倍,哈希取模算法的数据调整比例才会与一致性哈希算法打个平手,其余情形下,哈希取模都稍逊一筹,可参考下图:

节点减少时,也只有节点数量对半砍,哈希取模算法才能与一致性哈希算法的数据调整比例持平,否则,一致性哈希依然更胜一筹,就像下面这幅图展示的:

实现与应用
纸上得来终觉浅,了解了理论知识,如何落地实现并精准应用才是关键。
实现方式
哈希取模的代码实现简洁流畅,以 Java 语言为例:
import java.util.List;
public class HashModulo {
public static String getNode(List<String> nodes, String key) {
int hash = key.hashCode() & 0x7fffffff; // 保证非负
return nodes.get(hash % nodes.size());
}
public static void main(String[] args) {
List<String> nodes = List.of("Node1", "Node2", "Node3");
System.out.println(getNode(nodes, "Key1"));
System.out.println(getNode(nodes, "Key2"));
}
}
而一致性哈希算法则可以通过引用Guava实现:
import com.google.common.hash.Hashing;
import java.nio.charset.StandardCharsets;
import java.util.List;
public class GuavaConsistentHash {
public static String getNode(List<String> nodes, String key) {
int hash = Hashing.consistentHash(Hashing.murmur3_128().hashString(key, StandardCharsets.UTF_8), nodes.size());
return nodes.get(hash);
}
public static void main(String[] args) {
List<String> nodes = List.of("Node1", "Node2", "Node3");
System.out.println(getNode(nodes, "Key1"));
System.out.println(getNode(nodes, "Key2"));
}
}
应用场景
两种算法对比:
| 特性 | 一致性哈希 | 哈希取模 |
|---|---|---|
| 算法复杂度 | 较高 | 简单 |
| 扩展性 | 节点动态变化时影响较小 | 节点变化时需要重新分配所有数据 |
| 负载均衡 | 借助虚拟节点可实现更均衡的分布 | 容易因节点数量导致分布不均 |
| 典型应用场景 | 大型分布式系统 | 小规模分布式或单机场景 |
故障转移
一致性哈希:
- 故障节点的数据重新分布到哈希环上顺时针最近的节点。
- 数据迁移范围仅限失效节点附近,整体系统稳定性好。
- 可通过增加虚拟节点进一步减轻单节点故障的影响,确保数据在多个节点之间分布更均匀。
哈希取模:
- 故障节点会直接导致哈希空间的重新计算。
- 大量数据重新映射到其他节点,可能导致系统负载剧增,甚至无法响应请求。
- 对故障敏感,适合稳定、节点不经常失效的场景。
最佳实践:
- 如果节点可能频繁故障(如云环境),建议使用一致性哈希。
- 如果节点可靠性高且数量固定(如高可用物理服务器集群,例如DB、MQ等),可以使用哈希取模。
节点扩容
一致性哈希:
- 扩容时,只需将部分数据重新分配到新节点上。
- 迁移的数据量约为新增节点占总哈希空间的比例,迁移成本低。
- 支持动态扩展,适合需要弹性扩展的分布式系统(如缓存、文件存储)。
哈希取模:
- 扩容直接改变模的值(如从
n改为n+1)。 - 由于键的哈希值和新的模数可能不一致,大部分数据需要重新分配到新的节点。
- 不适合频繁扩展的场景,但在节点固定时表现良好。
最佳实践:
- 动态扩展场景(如云计算、分布式缓存):一致性哈希是首选。
- 固定节点场景(如垂直扩展的数据库集群):可以选择哈希取模。
小结
| 应用场景 | 推荐算法 | 原因 |
|---|---|---|
| 分布式缓存 | 一致性哈希 | 缓存服务器可能动态扩容或缩减,一致性哈希的数据迁移成本低,适合高可用环境。 |
| 分布式存储 | 一致性哈希 | 数据存储需要动态扩容和高可靠性,减少迁移数据量是关键。 |
| 简单负载均衡 | 哈希取模 | 如果节点数固定,且没有频繁扩容或故障,哈希取模实现简单且性能高。 |
| 日志收集与分析 | 一致性哈希 | 动态添加日志分析节点时,数据分布稳定性高,减少丢失和数据迁移。 |
| 数据库分片 | 哈希取模(节点固定时) | 数据库分片一般固定分片数,扩展场景较少,使用哈希取模性能更高且实现简单。 |
| 分布式消息队列 | 一致性哈希 | 消息队列通常需要动态扩展队列节点,使用一致性哈希可以减少迁移影响。 |
| 分布式缓存(节点固定) | 哈希取模 | 如果缓存节点固定,扩展需求低,哈希取模可以高效分布数据。 |
写在最后
通过对哈希取模和一致性哈希的详细介绍,我们清楚地看到了它们各自的优缺点和适用场景。在实际的分布式系统开发中,我们需要根据系统的特点和需求,谨慎选择合适的哈希算法,以确保系统的数据分布均匀、扩展性良好以及在面对节点故障和扩容时能够保持稳定高效的运行。希望这篇文章能够帮助大家更好地理解和应用这两种重要的哈希算法,为构建强大的分布式系统打下坚实的基础



评论区