




文章摘要(AI生成)
推荐系统是每个互联网公司面试中的经典考题,其设计难度源于复杂的数据处理、实时性要求和多维度的优化目标。推荐系统主要功能是帮助用户发现感兴趣的内容,从而提升转化率与用户黏性。系统设计首先要明确推荐场景,例如电商或内容平台,并根据不同业务目标定义推荐目标。数据来源和埋点设计是成功推荐系统的核心,确保高质量的数据收集、处理和特征生成是至关重要的。此外,通过构建用户画像和内容画像,系统能够进行有效的向量化匹配。召回层和排序层设计更进一步优化推荐结果,实现多路召回和智能排序。最后,实时性与模型更新和监控评估也是确保推荐效果的重要环节。本文将逐步拆解如何从零开始搭建一个高效的推荐系统。
一、引言:为什么推荐系统是系统设计的“必考题”
在系统设计面试中,“推荐系统(Recommendation System)”几乎是每家互联网公司都会问到的经典题目。无论是电商网站的“猜你喜欢”、视频平台的“为你推荐”、还是社交媒体的信息流算法,本质上都依赖推荐系统来提升用户粘性与转化率。
这道题的关键,不在于写出算法公式,而在于能否展示你对数据流、系统架构、模型服务化、实时计算等方面的系统性思考。
在这篇文章中,我们将通过一个具体场景(如电商或内容推荐),逐步拆解一个推荐系统是如何从 0 到 1 搭建起来的。
1.1 为什么推荐系统难?
推荐系统的复杂性在于它既要懂算法,又要懂工程实现。
- 数据量巨大:日志、用户行为、内容特征、上下文环境等。
- 实时性要求高:新用户注册、视频上传后,推荐结果必须快速响应。
- 多维度优化目标:既要提升点击率(CTR),又要控制多样性与公平性。
- 系统架构复杂:从离线特征计算到在线召回排序,涉及多种存储与计算引擎。
1.2 推荐系统的核心目标
推荐系统的目标可以简化为两句话:
帮助用户发现感兴趣的内容,帮助平台提升转化率和留存率。
为了实现这一点,我们通常会经历以下几个核心阶段:
- 数据收集与埋点
- 用户与内容建模
- 多路召回(Candidate Generation)
- 精排(Ranking)
- 重排与多样性控制(Re-Ranking)
- 实时更新与在线学习
二、需求分析与推荐目标确定
在系统设计题中,“搞清楚推荐什么、推荐给谁、为什么推荐” 是最核心的第一步。
推荐系统的设计永远是业务驱动的 —— 不同的场景下,推荐目标和优化方向都完全不同。
2.1 明确推荐场景
我们先假设两个典型场景:
场景一:电商平台(如京东、亚马逊)
- 目标:提升转化率和客单价。
- 推荐对象:商品。
- 数据来源:用户浏览、搜索、加购、下单、收藏等行为。
- 典型推荐模块:
- 首页推荐(个性化推荐)
- 详情页推荐(相似商品推荐)
- 购物车页推荐(关联购买推荐)
- 结算页推荐(补充购买推荐)
场景二:内容平台(如抖音、知乎、B站)
- 目标:提升用户停留时长与互动率。
- 推荐对象:视频、文章、问答。
- 数据来源:点赞、评论、停留时长、关注、转发等行为。
- 典型推荐模块:
- 信息流推荐(Feed流)
- 相关推荐(相似主题)
- 热门内容(全局召回)
2.2 明确系统目标
推荐系统往往有多重目标,需要综合考虑:
| 目标类型 | 示例 | 说明 |
|---|---|---|
| 业务目标 | 提升点击率(CTR)、转化率(CVR) | 直接影响营收或活跃度 |
| 用户目标 | 提高满意度、减少审美疲劳 | 保持用户粘性与体验 |
| 系统目标 | 支持大规模数据与实时计算 | 保证稳定性与可扩展性 |
| 算法目标 | 平衡精准度与多样性 | 防止“信息茧房”问题 |
2.3 推荐流程全景图(简化)
推荐系统的整体流程通常如下:
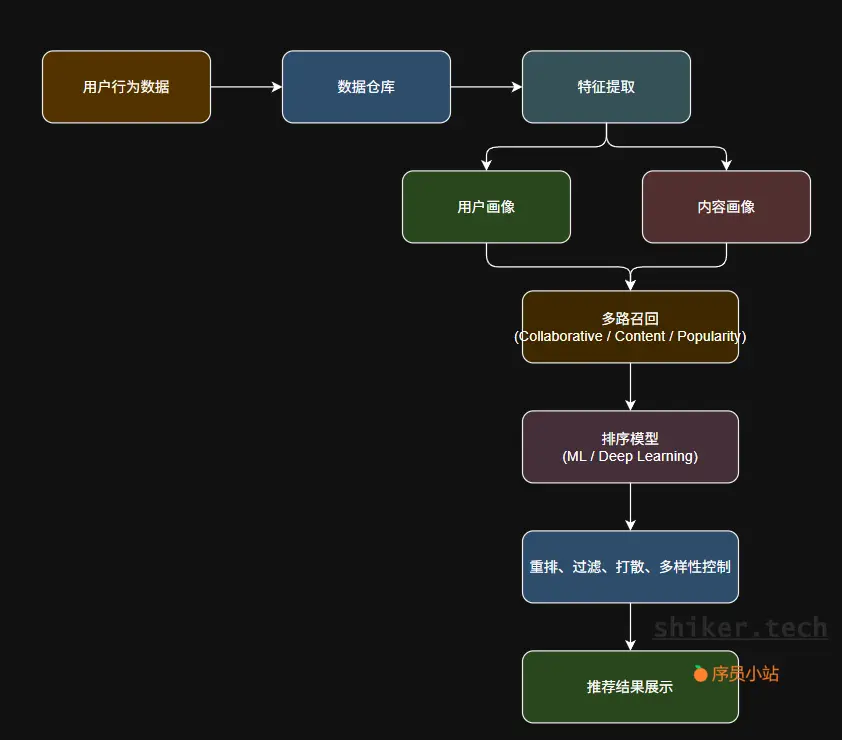
2.4 面试时答题技巧
在面试中,这一部分可以用 30 秒讲清楚逻辑:
“我会先根据业务目标确定推荐系统类型,比如是电商场景提升转化,还是内容场景提升留存。接着定义推荐目标(CTR、CVR),再根据这些目标规划后续的架构模块,包括召回、排序、重排等。”
如果能顺带说出“多目标优化”“冷启动问题”“实时更新”等关键词,面试官会认为你有过实际项目经验。
三、数据来源与埋点设计
推荐系统的核心在于“数据”。
一句话总结就是:
没有高质量的数据,就没有高质量的推荐。
一个推荐系统的效果,70% 取决于数据,算法和模型只占 30%。因此在系统设计题中,面试官非常关注你如何获取、处理并使用数据。
3.1 数据来源分类
推荐系统中的数据可分为三大类:
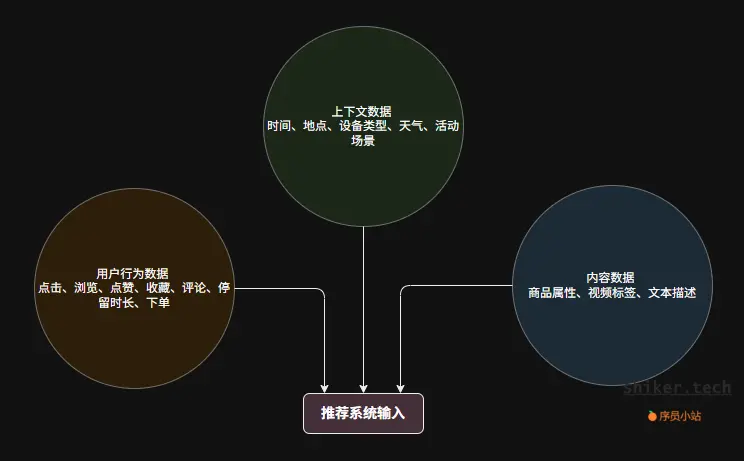
举例:
- 用户在晚上打开外卖 App,更可能看到夜宵类推荐;
- 用户刚搜索“篮球鞋”,推荐页可以优先展示运动装备。
3.2 埋点设计(Tracking & Logging)
为了采集用户行为数据,我们需要设计合理的埋点系统。
(1)前端埋点
-
通过 JS SDK、App SDK 记录用户操作事件;
-
示例:
{ "event": "click_item", "userId": "u123", "itemId": "i567", "page": "home", "timestamp": "2025-10-12T12:30:00Z" } -
每个埋点事件都应包含:用户ID、内容ID、行为类型、时间戳、上下文信息。
(2)服务端日志
- 对于支付、下单等关键行为,必须服务端埋点,避免前端数据造假;
- 通常写入 Kafka、Pulsar 等日志队列。
(3)埋点系统要求
- 标准化:事件命名、字段定义一致;
- 实时性:支持实时流入 Flink / Spark Streaming;
- 可扩展性:新增埋点事件不影响旧系统;
- 可监控:埋点缺失或延迟要有报警机制。
3.3 数据处理与特征生成
埋点只是“收集”,真正的关键是“清洗”和“建模”。
推荐系统的数据处理流程如下:
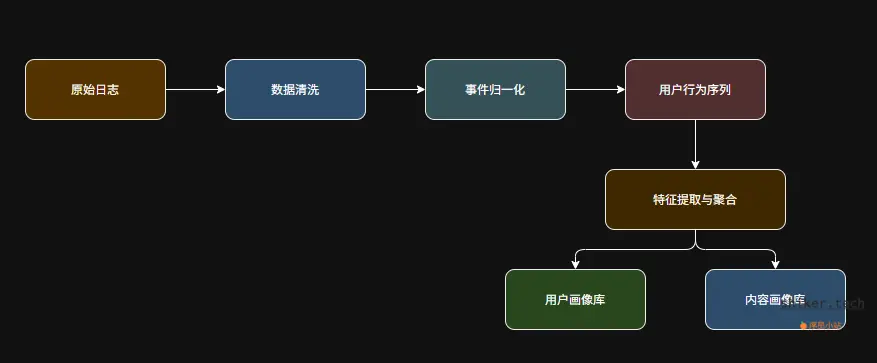
常见的特征:
- 用户特征:年龄、性别、偏好标签、最近活跃时间;
- 内容特征:主题、热度、标签、发布时间;
- 行为特征:最近点击的类别分布、7日活跃次数。
3.4 冷启动问题
当用户或内容刚进入系统时,推荐系统缺乏数据。
需要设计冷启动策略:
| 冷启动类型 | 解决策略 |
|---|---|
| 新用户冷启动 | 用注册信息或地理位置推荐热门内容(基于群体特征) |
| 新内容冷启动 | 利用内容标签或文本相似度召回相似内容 |
| 系统冷启动 | 先用规则或人工推荐,逐步引入算法推荐 |
3.5 面试技巧总结
如果你在面试中讲到这一部分,可以强调以下几点:
- “推荐系统的数据采集必须精准埋点,否则模型学习不到真实偏好”;
- “我会把前端行为日志通过 Kafka 汇入数据仓库,Flink 实时清洗生成特征”;
- “同时考虑冷启动与数据延迟问题,通过多源融合保证系统稳定”。
这样能体现你具备数据工程与推荐架构的综合思维。
四、用户画像与内容画像建模
推荐系统的本质是“匹配”——
把用户画像(User Profile)与内容画像(Item Profile)进行匹配,从而找到最合适的推荐内容。
而用户画像与内容画像的好坏,直接决定了系统推荐的精准度和个性化程度。
4.1 用户画像(User Profile)
用户画像的目标是用数据刻画“这个人是谁、喜欢什么、近期在关注什么”。
通常可分为以下几类:
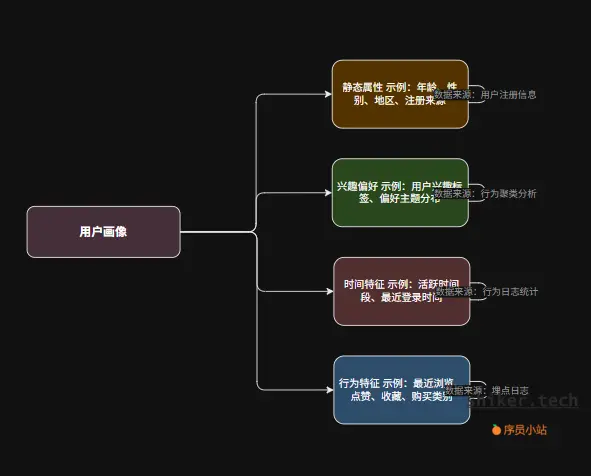
示例:用户画像结构
{
"userId": "u123",
"age": 27,
"gender": "male",
"city": "Shanghai",
"interests": ["篮球", "数码", "AI技术"],
"active_hours": [20, 22],
"recent_click_categories": ["运动鞋", "耳机"]
}
特征提取方法
- 统计特征:过去7天点击次数、收藏次数;
- Embedding 表征:通过模型学习,将用户行为序列编码为向量;
- 聚类分析:将用户按行为聚为不同兴趣群体;
- 时序特征:分析行为变化趋势(如兴趣迁移)。
4.2 内容画像(Item Profile)
内容画像用于描述“这个内容是什么”,是推荐系统的另一半。
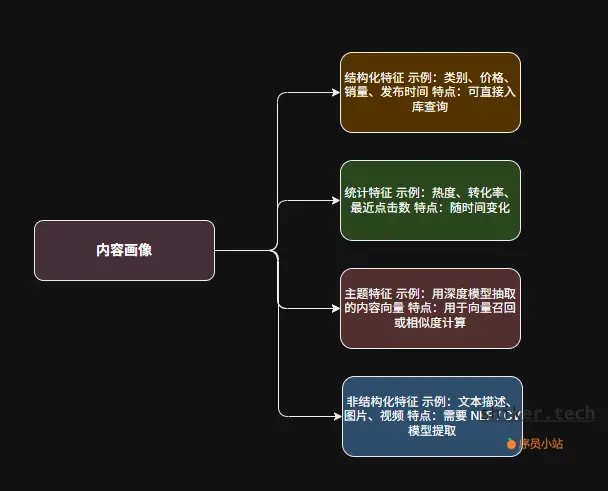
示例:内容画像结构
{
"itemId": "i789",
"category": "运动鞋",
"price": 499,
"tags": ["篮球", "NIKE", "新品"],
"popularity": 0.78,
"embedding": [0.12, 0.87, 0.56, ...]
}
特征提取方法
- 关键词抽取:TF-IDF / TextRank;
- 语义表示:BERT、Word2Vec、S-BERT 等模型;
- 图像特征提取:ResNet / CLIP;
- 多模态融合:融合文本 + 图片 + 标签信息生成统一向量。
4.3 用户与内容的向量化匹配
推荐系统常用的方法是将用户与内容都映射到同一个向量空间中:
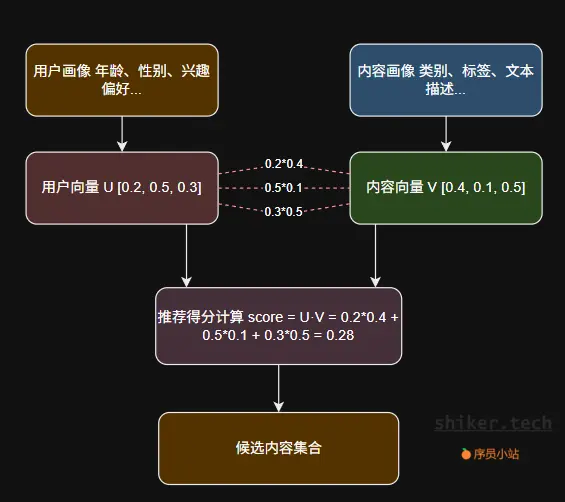
这种方式被广泛用于召回阶段(Candidate Generation),能高效地从海量内容中筛选出候选集合。
4.4 数据存储与更新
| 模块 | 存储方式 | 更新频率 |
|---|---|---|
| 用户画像库 | Redis / ElasticSearch / HBase | 实时或分钟级 |
| 内容画像库 | MySQL / ElasticSearch / 向量数据库(Milvus、Faiss) | 小时级或天级 |
| 用户行为日志 | Kafka / HDFS / ClickHouse | 实时流入 |
推荐系统需保证:
- 用户画像实时更新:行为变化能快速反映;
- 内容画像批量更新:新内容及时入库、老内容定期重算。
4.5 面试技巧总结
在系统设计题中,讲到用户和内容画像时可以这样表达:
“我会用用户画像和内容画像建立语义层的匹配基础。用户画像包括静态特征与行为序列;内容画像包括结构化与语义特征。两者都以向量化形式存储,支持高效相似度召回。”
面试官听到“向量化”“多模态”“实时画像”这些关键词,通常会认为你对推荐系统理解深入。
五、召回层设计:快速生成候选集
在推荐系统中,候选集的生成(Candidate Generation)是第一道关键筛选。
它的任务是:
在海量内容中快速找出“可能感兴趣”的一小部分供后续排序使用。
可以理解为:召回层负责“广撒网”,排序层负责“精挑细选”。
5.1 为什么要有召回层
假设系统有 1000 万条内容,不可能每次都对全部内容计算相似度或排序得分。
所以通常采用两级结构:
用户请求 → 召回层(筛选 1000 个候选) → 排序层(挑选前 50 条展示)
召回层需要做到:
- 高召回率:尽量覆盖用户可能感兴趣的内容;
- 低延迟:毫秒级返回;
- 多样性:召回结果不能太集中。
5.2 常见召回策略
推荐系统通常采用 多路召回(Multi-Recall),不同策略独立生成候选集,然后再合并。
| 召回方式 | 思想 | 优点 | 缺点 |
|---|---|---|---|
| 协同过滤(CF)召回 | “相似用户喜欢的内容” | 简单、解释性强 | 新用户冷启动难 |
| 内容相似召回 | “相似内容推荐” | 支持新内容冷启动 | 个性化弱 |
| Embedding 召回 | “向量相似度匹配” | 高效、可扩展 | 依赖模型训练 |
| 热门召回 | “全站最热门内容” | 快速提升点击率 | 多样性差 |
| 规则召回 | “根据业务策略” | 可控性强 | 难以个性化 |
| 社交召回 | “好友看过/互动内容” | 粘性强 | 数据依赖大 |
通常一个系统会组合 5~10 路召回结果。
例如:
协同过滤召回 + 内容相似召回 + 热门召回 + 新品召回 + 用户兴趣召回
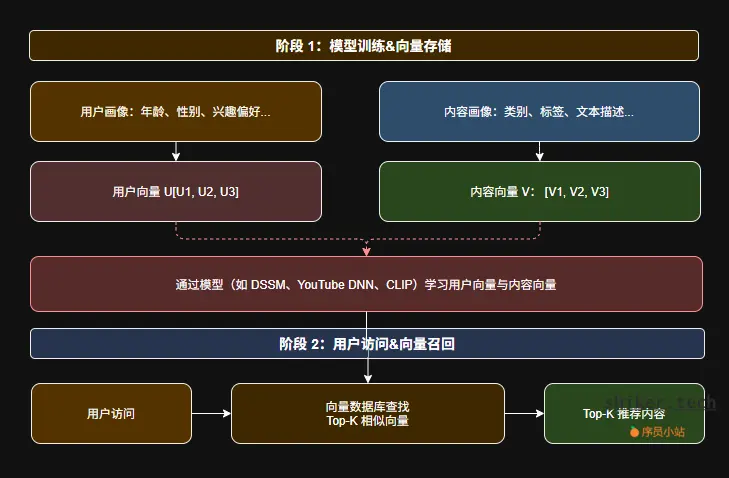
5.3 向量召回(Embedding Recall)
现代推荐系统普遍使用 向量召回(Vector Search) 机制。
流程如下:
- 通过模型(如 DSSM、YouTube DNN、CLIP)学习用户向量与内容向量;
- 存入向量数据库(如 Faiss、Milvus、Elastic Vector Search);
- 用户访问时计算相似度(cosine / dot product),取 Top-K 内容。
示例伪代码:
results = vector_db.search(user_vector, top_k=200)
这一步通常可在 10~50ms 内完成。
5.4 多路召回融合策略
多路召回的结果可能重复或冲突,需要统一处理:
- 去重:按内容ID合并;
- 加权融合:给每种召回类型分配权重;
- 打分排序:可使用线性加权或简单模型融合;
- 多样性打散:避免同一类别内容过多。
融合示例:
FinalScore = 0.4 * CF + 0.3 * ContentSim + 0.2 * Hot + 0.1 * Social
5.5 数据存储与性能优化
| 模块 | 技术方案 | 说明 |
|---|---|---|
| 向量检索 | Faiss、Milvus、Elastic Vector | 支持 ANN(近似最近邻搜索) |
| 热门召回 | Redis SortedSet | 快速取 TopN |
| 协同过滤 | Spark / Flink + Redis Cache | 周期性生成相似度矩阵 |
| 内容相似 | ElasticSearch + 语义索引 | 文本/标签相似检索 |
性能优化技巧:
- 召回结果缓存(热门用户请求缓存几分钟);
- 召回层异步调用(并行多路召回);
- 预计算热门内容 embedding;
- 使用 ANN(Approximate Nearest Neighbor)算法加速检索。
5.6 面试答题技巧
当面试官问到召回阶段,你可以用这段话概括:
“召回层的目标是在毫秒级内从海量内容中筛选候选集。我会采用多路召回策略,比如协同过滤、内容相似、向量召回和热门召回。每种召回结果融合后进入排序层。底层使用向量数据库(如 Faiss 或 Milvus)支持高效检索,并通过缓存和异步请求优化性能。”
六、排序层设计:机器学习与特征工程
召回层的目标是“找到可能感兴趣的内容”,而**排序层(Ranking)**的任务则是:
从召回的几千条候选中,精确挑选出最值得展示的几十条。
这一层是推荐系统的“智能核心”,直接决定推荐效果的好坏。
6.1 排序层的核心思路
排序层通过机器学习模型(ML Model)对每条候选内容进行打分,打分结果通常代表用户与内容之间的“交互概率”,如:
- 点击概率(CTR)
- 转化概率(CVR)
- 停留时间(Watch Time)
- 复购率(Retention Rate)
最终的推荐得分可能是多目标综合计算:
[
score = w_1 \times CTR + w_2 \times CVR + w_3 \times Retention
]
6.2 排序模型选择
排序层模型从传统ML到深度学习,常见方案如下:
| 模型 | 优点 | 适用场景 |
|---|---|---|
| LR(逻辑回归) | 线性、可解释性强 | CTR预估的基线模型 |
| GBDT / XGBoost | 非线性特征强 | 中小规模数据、可快速上线 |
| Wide & Deep | 结合线性与深度特征 | 谷歌推荐系统经典模型 |
| DeepFM / DIN / DIEN | 建模高阶交互和序列兴趣 | 内容推荐主流模型 |
| Transformer-based | 捕捉长序列依赖 | 高级兴趣建模(如抖音、B站) |
典型生产系统一般会采用:
召回:ANN模型
排序:Wide & Deep / DeepFM
重排:轻量级DNN或规则模型
6.3 模型训练与部署
(1)训练阶段
- 采集用户日志(曝光、点击、转化等);
- 样本构建:点击为正样本、曝光未点击为负样本;
- 训练目标:最小化交叉熵或最大化AUC;
- 定期(如每天)离线重训并评估模型效果。
(2)在线预测阶段
- 用户访问页面时,系统实时加载特征;
- 模型推理(Inference)计算每个候选的打分;
- 根据得分排序,输出Top N条推荐内容。
通常延迟需控制在 <100ms。
6.4 排序层优化策略
| 优化方向 | 说明 |
|---|---|
| 特征筛选与归一化 | 减少噪声特征、提升模型泛化能力 |
| 多目标学习(Multi-Task) | 同时优化点击与转化 |
| 时间衰减权重 | 近期行为影响更大 |
| 采样平衡 | 解决点击样本稀疏问题 |
| 实时学习(Online Learning) | 让模型快速适应趋势变化 |
| 模型蒸馏(Distillation) | 用轻模型替代复杂模型部署 |
6.5 面试答题技巧
在系统设计面试中讲排序层时,你可以简要表述如下:
“在排序阶段,我会将召回结果输入一个机器学习模型,如Wide & Deep或DeepFM。特征包括用户画像、内容画像和交叉特征。模型目标是预估点击率(CTR)或综合得分,最终在毫秒级内完成在线推理。特征由Flink实时生成,模型每日训练并热更新。”
关键词建议包含:
- “CTR预估”
- “Wide & Deep”
- “特征交叉”
- “在线推理”
- “延迟优化”
七、实时性与模型更新策略
推荐系统的效果,往往与“实时性”息息相关。用户兴趣会随时间快速变化,若系统不能及时捕捉这些变化,就会出现“推荐滞后”的问题。例如,用户刚浏览完一款手机,却仍被推荐相同型号的广告,这是典型的实时性不足。
7.1 实时性的核心挑战
推荐系统中存在两类实时需求:
- 用户行为实时更新:如点击、收藏、购买等行为需要实时写入用户画像;
- 推荐结果实时响应:用户打开页面时,系统需在毫秒级内生成个性化推荐结果。
这要求我们在数据流与模型层面同时优化。
7.2 实时数据流处理
为了支持实时用户行为更新,我们可以采用流式计算框架(如 Kafka + Flink 或 Spark Streaming):
- 数据采集层:前端埋点数据通过 SDK 实时上报;
- 消息队列:Kafka 负责削峰填谷、保证顺序;
- 流式处理层:Flink 实时计算用户最新特征(例如“最近5分钟点击次数”、“上次登录时间”);
- 特征存储层:计算结果写入 Redis 或特征库(Feature Store),供排序模型使用。
这套流程可以确保:
用户在5秒前刚点击的内容,下一次推荐请求就能被系统感知。
7.3 模型更新策略
推荐系统中的模型可分为两种更新机制:
(1)离线周期性训练
- 批处理方式(如每天训练一次)
- 优点:模型稳定、训练成本低
- 缺点:响应慢,无法及时反映新热点
(2)在线增量训练
- 模型在新数据到达时持续更新(如使用在线学习算法、参数服务器)
- 优点:适应性强,可捕捉实时趋势
- 缺点:实现复杂,对系统一致性要求高
在实际场景中,通常采用混合策略:
离线模型负责长期稳定性,在线模型负责短期动态性。
7.4 热点内容的实时推荐
除了用户行为更新,系统还需感知内容热度。例如在短视频平台中,一条视频突然爆火时,需要即时推送给更多用户。
可使用实时热点检测算法(如滑动窗口统计或指数衰减权重)识别内容热度,将其注入召回候选集,以保证推荐时效。
7.5 实时架构示例
[前端埋点] → [Kafka 消息队列] → [Flink 实时特征计算] → [Redis 特征库] → [在线排序服务] → [推荐结果返回]
这条数据流实现了“用户行为→特征更新→推荐响应”的闭环,是真实推荐系统的“心跳通道”。
八、监控与效果评估指标
推荐系统是否“好用”,不能凭主观感觉判断,而要通过精确的指标体系与科学的实验方法来验证。
这一章,我们将介绍推荐系统的关键评估指标、监控体系,以及如何构建A/B测试机制,让推荐优化有据可依。
8.1 推荐系统效果评估的两大类型
推荐系统的效果评估可分为两类:
- 离线评估(Offline Evaluation)
在历史数据上模拟推荐结果,衡量模型预测准确度; - 在线评估(Online Evaluation)
在真实环境中对用户行为进行实验观察,如A/B测试。
两者的关系:
离线评估用来筛选候选模型,在线评估用来验证实际收益。
8.2 常见离线指标
(1)准确率(Precision)与召回率(Recall)
衡量推荐结果是否命中用户真正感兴趣的内容。
- Precision = 推荐中相关的内容数 / 推荐总数
- Recall = 推荐中相关的内容数 / 所有相关内容数
(2)NDCG(Normalized Discounted Cumulative Gain)
综合考虑推荐排序的合理性:
越靠前的内容越应重要,越被点击的权重越高。
(3)AUC(Area Under Curve)
衡量模型区分正负样本的能力,是CTR模型常用的指标。
(4)覆盖率与多样性
不能总推荐热门内容,系统还需具备推荐“长尾内容”的能力。
- 覆盖率:推荐内容数 / 全部内容数
- 多样性:推荐结果间的相似度越低越好
8.3 在线评估指标(核心业务指标)
在线指标更直接反映业务收益,常见包括:
| 指标 | 含义 | 示例 |
|---|---|---|
| CTR | 点击率 | 用户点击的推荐数 / 展示的推荐数 |
| CVR | 转化率 | 购买、播放、注册等行为 / 点击数 |
| Watch Time | 用户停留时长 | 视频类推荐常用指标 |
| DAU/留存率 | 用户活跃情况 | 衡量长期用户价值 |
| Revenue | 收入 | 广告、电商推荐系统关键指标 |
8.4 A/B测试体系设计
A/B测试是推荐系统优化的“金标准”。
核心流程如下:
- 流量分桶
将用户随机划分为实验组(新模型)与对照组(旧模型); - 统一埋点
确保两组数据采集一致,避免统计偏差; - 监控指标变化
重点观察CTR、CVR、留存等变化; - 显著性检验
通过统计方法(如t检验)判断结果是否显著优于旧模型; - 灰度发布与全量推广
若实验结果正向且稳定,则逐步放量上线。
8.5 监控与报警体系
推荐系统是高复杂度系统,任何环节异常都可能导致推荐质量骤降。
因此需要建立全链路监控:
| 模块 | 监控项 | 报警条件 |
|---|---|---|
| 数据采集 | 日志延迟、丢包率 | 延迟 > 1分钟 |
| 流式计算 | Kafka/Flink 吞吐量 | 消息堆积、Task Fail |
| 特征服务 | 缓存命中率、请求延时 | 命中率 < 90%,延时 > 200ms |
| 模型服务 | QPS、错误率 | 错误率 > 1% |
| 业务指标 | CTR/CVR 波动 | 日环比下降超10% |
通过 Prometheus + Grafana 实现实时可视化,结合报警机器人(如钉钉/Slack),可以让系统稳定运行。
8.6 指标体系的最终目标
指标的意义不在于数据本身,而在于指导优化。
推荐系统的评估体系应做到:
- 定量衡量效果;
- 快速定位问题;
- 驱动模型与算法持续迭代。
九、总结与系统设计答题技巧
到这里,我们已经从需求分析 → 数据建模 → 召回排序 → 在线架构 → 实时性 → 评估体系,完整走完了一套推荐系统设计流程。
这一章将帮助你把这些内容结构化表达,在系统设计题中展现出“清晰的思路 + 体系化的设计能力”。
9.1 推荐系统设计核心思路回顾
你可以在答题或面试时用这条逻辑链来回答问题:
需求 → 数据 → 模型 → 系统架构 → 实时性 → 评估
| 模块 | 核心要点 |
|---|---|
| 需求分析 | 明确推荐目标(如提升CTR、转化率) |
| 数据采集 | 用户行为、内容属性、上下文环境 |
| 特征建模 | 用户画像、内容画像、上下文特征 |
| 召回层 | 多路召回(协同过滤、内容相似、热门) |
| 排序层 | 机器学习模型(LR、GBDT、DeepFM等) |
| 重排与多样性 | 控制热门内容占比,提升推荐新鲜度 |
| 在线服务 | 缓存层(Redis)、特征服务、排序服务 |
| 实时更新 | Kafka + Flink 架构,支持实时特征计算 |
| 效果评估 | CTR、CVR、NDCG、A/B测试、稳定性监控 |
9.2 面试中的答题模板(STAR结构)
在系统设计面试中,时间通常只有15分钟,你可以用以下模板快速组织答案:
S(Situation)场景:
我们要为一个电商/视频平台设计推荐系统,目标是提升CTR和用户留存。
T(Task)目标:
设计可扩展、低延迟、支持实时更新的推荐架构。
A(Action)方案:
- 从日志埋点获取用户行为数据;
- 构建用户与内容画像;
- 使用多路召回 + 精排模型;
- 引入Redis加速在线推荐;
- Flink实时更新用户特征。
R(Result)结果:
系统可在100ms内响应推荐请求,CTR提升15%,实现A/B测试闭环。
这样答题不仅逻辑清晰,还能体现出你的系统性思维与业务意识。
9.3 推荐系统设计的延伸方向
如果你想在面试或实践中进一步拓展,可以从以下方向深入:
- 向量检索(ANN):使用Faiss、Milvus加速高维召回;
- 多目标优化(Multi-Task Learning):同时优化CTR、CVR;
- 强化学习推荐:通过Reward信号自适应推荐策略;
- 大模型助力:使用LLM生成特征或冷启动推荐描述;
- 多模态推荐:结合文本、图片、音频特征提升效果。
这些方向通常是面试中“加分项”,也能展示你具备系统设计的前瞻性思维。
9.4 结语
推荐系统的设计是一门“工程 + 算法 + 产品”结合的艺术。
无论你面对的是面试题,还是实际项目,都可以遵循以下心法:
先定义目标,再搭建架构,最后用数据验证。
系统设计没有唯一答案,最好的方案永远是:
符合业务场景、能快速迭代、具备可扩展性。



评论区