




文章摘要(AI生成)
本论文探讨了全局唯一 ID 生成器的设计与实现,系统分为七章。首先,需求分析明确了功能与非功能需求,包括唯一性、高可用性和高性能等关键要素,并提出面试中常见的引导问题。接下来,详细介绍了三种 ID 类型及其优缺点:UUID、数据库自增 ID 和分布式 Snowflake 方案。核心设计思路部分讨论了集中式与分布式生成的利弊、ID 组成、唯一性保证策略以及性能优化点。系统架构设计章节则强调高可用性与可扩展性,建议通过多机房部署和动态机器 ID 分配来增强系统的容错能力。最后,具体实现方案包括单机与分布式 Snowflake 的实现细节,并提供了异常处理及简化版 Java 代码示例。本文的目标是帮助读者掌握全局唯一 ID 生成的关键技术,同时提高在技术面试中的表现。
引言
在互联网和分布式系统中,全局唯一 ID 是几乎每个业务系统都会遇到的基础设施需求。无论是订单号、用户 ID,还是日志追踪、分布式缓存的 key,都离不开一个可靠、唯一的标识符生成机制。
在技术面试中,设计一个全局唯一 ID 生成器是非常典型的系统设计题目。考官不仅希望看到你对技术的掌握,还希望考察你对高可用性、分布式一致性、性能优化等核心问题的理解。
本文旨在通过一个完整的分析流程,带你从需求出发,理解全局唯一 ID 的生成原理、设计思路、架构方案,甚至落地实现,并结合面试中的答题技巧,让你在面试中能够条理清晰地展示自己的思路。

第一章:需求分析
在设计全局唯一 ID 生成器之前,首先要明确系统的需求,这不仅是面试考察的重点,也是实际工程中能否落地的关键。
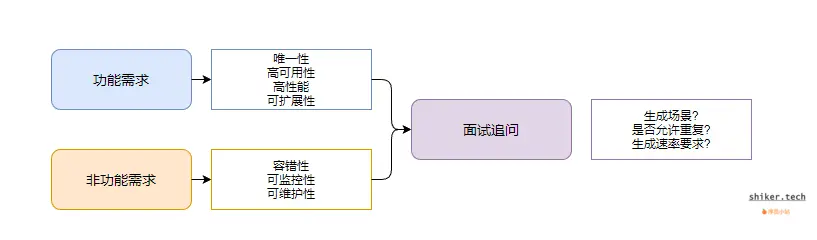
1. 功能需求
- 唯一性
ID 必须全局唯一,不能出现重复,否则可能导致数据冲突或业务异常。 - 高可用性
系统在高并发和节点故障时仍需正常生成 ID,不成为业务瓶颈。 - 高性能
能够在短时间内生成大量 ID,满足分布式业务的请求压力。 - 可扩展性
系统应支持水平扩展,以应对业务量增长。
2. 非功能需求
- 容错性
系统应能容忍机器宕机、网络延迟或时钟回拨等异常情况。 - 可监控性
需要对生成 ID 的数量、性能指标和异常情况进行监控。 - 可维护性
系统架构清晰,便于后续升级和优化。
3. 面试角度的引导问题
在面试中,考官通常会通过追问来考察你的思路,典型问题包括:
- 生成 ID 的场景:订单号、用户 ID、日志追踪等,明确使用场景有助于选择生成方案。
- 是否允许重复:了解业务是否可以容忍重复,以平衡性能和复杂度。
- 生成速率要求:帮助设计高性能方案,判断是否需要分布式生成。
明确需求是设计的第一步,也是你在面试中展示逻辑清晰的关键环节。
第二章:全局唯一 ID 的类型与特点
了解不同类型的全局唯一 ID 及其特点,有助于在面试中快速选择合适的方案,并能够解释设计取舍。
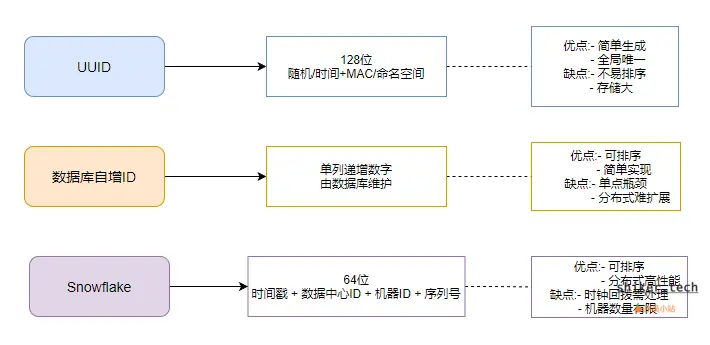
1. UUID(通用唯一标识符)
特点:
- 通常长度为 128 位,生成方式依赖时间戳、随机数或哈希算法。
- 可以在分布式系统中直接生成,无需集中服务。
优点:
- 简单易用,不依赖中心节点。
- 几乎保证全局唯一。
缺点:
- 不易排序,不利于按时间查询。
- 存储空间大(16 字节或 36 字符)。
- 可读性差,调试和日志中不直观。
适用场景:
- 对性能要求高、但不需要连续 ID 的场景,如日志 ID、追踪 ID。
2. 数据库自增 ID
特点:
- 依赖数据库的自增列(AUTO_INCREMENT 或序列)。
- 单机数据库天然保证唯一性。
优点:
- 简单、可排序。
- 便于调试和分析。
缺点:
- 单点瓶颈,数据库压力大时性能受限。
- 分布式扩展困难,需要额外协调机制(如数据库分片或中间件)。
适用场景:
- 单机业务系统,或分库分表情况下,通过分片保证唯一性。
3. Snowflake 方案(分布式 ID 生成器)
特点:
- 由 Twitter 提出的分布式 ID 生成方案。
- ID 通常由时间戳 + 数据中心 ID + 机器 ID + 序列号组成。
- 支持高并发、分布式生成,同时保证唯一性。
优点:
- 可排序(按时间戳)。
- 分布式生成,高性能,支持水平扩展。
缺点:
- 时钟回拨可能导致重复,需要特殊处理。
- 机器数量和序列号位数有限制。
适用场景:
- 高并发分布式系统,如电商订单号、社交平台内容 ID、日志系统等。
掌握这些 ID 类型及其优缺点,能够帮助你在面试中快速提出方案,并结合需求说明选择理由。
第三章:核心设计思路
在明确需求和了解 ID 类型后,下一步是设计全局唯一 ID 生成器的核心思路。这里以分布式系统为背景,主要关注如何保证唯一性、高性能和可扩展性。
1. 集中式 vs 分布式生成
| 方案 | 优点 | 缺点 |
|---|---|---|
| 集中式 | 简单,容易保证唯一性 | 单点瓶颈,高并发压力大,容错困难 |
| 分布式 | 高性能,可水平扩展 | 需要解决机器 ID 分配、时钟回拨等问题 |
面试中可以先分析两种方案的利弊,再选择分布式方案作为主流实现。
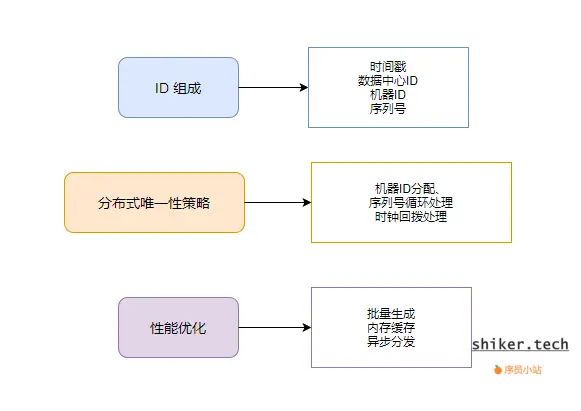
2. ID 组成设计
以 Snowflake 为例,ID 通常由以下几部分组成:
- 时间戳(Timestamp)
- 保证生成顺序性。
- 一般使用毫秒级或微秒级时间戳。
- 机器 ID / 数据中心 ID(Worker ID / Datacenter ID)
- 用于区分不同节点,保证分布式环境下唯一性。
- 序列号(Sequence Number)
- 在同一毫秒内生成多个 ID 时递增,防止冲突。
ID = 时间戳 + 数据中心 ID + 机器 ID + 序列号
3. 分布式唯一性保证策略
- 机器编号分配
- 静态配置或通过 Zookeeper/Redis 分配。
- 避免不同节点使用相同机器 ID。
- 序列号循环与溢出处理
- 序列号用完时,可等待下一毫秒再生成,保证唯一性。
- 时钟回拨处理
- 遇到系统时间回拨,可暂停生成或使用逻辑时钟。
4. 性能优化点
- 批量生成:一次生成多个 ID,减少网络或计算开销。
- 内存缓存:预先生成 ID 存入缓存,加快分发速度。
- 异步分配:生成 ID 与业务请求异步,提高吞吐量。
这一节的核心是:先拆分 ID 组成,明确每一部分的作用,再考虑分布式唯一性和性能优化策略,这样设计思路清晰,面试讲解也更有条理。
第四章:系统架构设计
在明确核心设计思路后,下一步是绘制系统架构,考虑高可用性、可扩展性以及分布式部署。
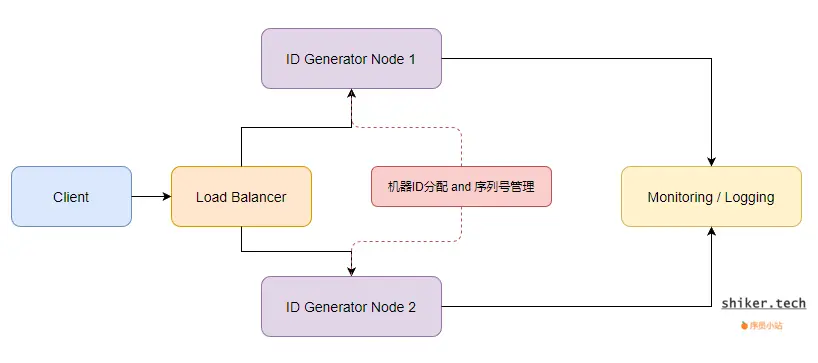
1. 整体架构
一个典型的全局唯一 ID 生成器系统由以下几个模块组成:
- ID 生成服务
- 核心模块,负责生成唯一 ID。
- 每台机器根据配置的机器 ID 生成 ID。
- 客户端调用方式
- 可以通过 RPC 或 HTTP 接口调用生成服务。
- 支持批量获取 ID。
- 数据存储与监控
- 监控生成速率、延迟和异常情况。
- 可选的持久化存储,用于统计或故障恢复。
架构图示意:
2. 高可用设计
- 多机房部署
- 避免单机房宕机导致生成服务不可用。
- Leader 选举机制(可选)
- 当使用集中式或协调机器 ID 时,通过 Zookeeper 等实现 Leader 节点管理。
- 容错与降级策略
- 节点宕机时,其他节点接管生成任务。
- 临时缓存 ID 或返回备用方案。
3. 扩展性设计
- 水平扩展
- 新节点加入时分配唯一机器 ID,自动参与生成。
- 动态分配机器 ID
- 通过注册中心(如 Zookeeper、Etcd、Consul)动态分配,避免重复冲突。
- 接口与协议设计
- 简单的 API:
getNextID()、getBatchID(count) - 支持高并发调用,保证线程安全和非阻塞性能。
- 简单的 API:
这一节强调架构设计,目的是让面试官看到你对分布式、高可用、可扩展系统的全局把控能力,同时也为后续具体实现打下基础。
第五章:具体实现方案
在明确了架构和设计思路后,下一步是将理论落地,讨论具体的实现方式,以及应对各种异常的处理策略。
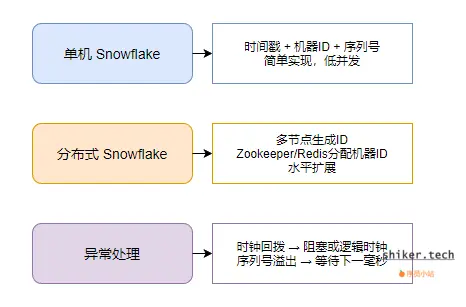
1. 单机 Snowflake 实现
- 核心思想:每台机器生成 ID 时,只需保证本机唯一序列号。
- 组成结构:
- 时间戳(毫秒级)
- 机器 ID
- 序列号(同一毫秒内递增)
- 特点:
- 简单,适合低并发场景或测试环境。
- 无需外部依赖。
2. 分布式 Snowflake 实现
- 核心问题:如何在多台机器上生成 ID 并保证全局唯一。
- 常用方案:
- Zookeeper 分配机器 ID
- 集群节点注册时分配唯一机器 ID。
- 利用 Zookeeper 的节点顺序和注册机制保证不重复。
- Redis 或数据库分配机器 ID
- 通过分布式锁或者自增值分配机器 ID。
- 保证新增节点不与已有节点冲突。
- Zookeeper 分配机器 ID
- 特点:
- 支持水平扩展。
- 高并发生成,延迟低。
3. 异常处理
- 时间回拨
- 如果系统时钟回拨,序列号可能重复。
- 常见解决方案:
- 阻塞等待直到系统时间追上上一次生成时间。
- 使用逻辑时钟(时间戳递增值)代替真实时间。
- 序列号溢出
- 在同一毫秒生成 ID 数量超过序列号位数。
- 处理方式:
- 等待下一毫秒再生成。
- 适当增加序列号位数(例如 12 位)。
4. 代码示例(简化版 Java)
public class SnowflakeIdGenerator {
private final long workerId;
private long lastTimestamp = -1L;
private long sequence = 0L;
private final long sequenceBits = 12L;
public SnowflakeIdGenerator(long workerId) {
this.workerId = workerId;
}
public synchronized long nextId() {
long timestamp = System.currentTimeMillis();
if (timestamp < lastTimestamp) {
throw new RuntimeException("Clock moved backwards!");
}
if (timestamp == lastTimestamp) {
sequence = (sequence + 1) & ((1 << sequenceBits) - 1);
if (sequence == 0) {
while (System.currentTimeMillis() <= lastTimestamp) {}
timestamp = System.currentTimeMillis();
}
} else {
sequence = 0;
}
lastTimestamp = timestamp;
return ((timestamp << (10 + sequenceBits)) | (workerId << sequenceBits) | sequence);
}
}
- 示例仅展示核心生成逻辑,面试中可用此说明思路。
- 分布式实现时,增加机器 ID 动态分配即可。
这一节的重点是将设计方案落地,包括单机和分布式两种方案、异常处理,以及简单代码示例,让面试官直观理解你的实现能力。
第六章:面试答题技巧
在面试中,设计全局唯一 ID 生成器不仅考察技术能力,还考察表达能力和逻辑思路。掌握以下技巧,可以让你的回答更加条理清晰。
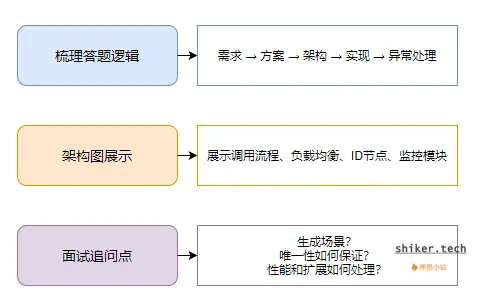
1. 如何拆解需求
- 明确功能:唯一性、高并发、可扩展。
- 明确非功能:容错、监控、可维护。
- 分层说明:先说明单机方案,再扩展到分布式。
面试回答示例:“首先,我会明确 ID 的唯一性和生成速率需求;其次,如果业务量大,我会采用分布式方案,确保高可用和水平扩展。”
2. 如何用架构图说明思路
-
简单画出模块与调用关系:
Client → Load Balancer → ID Generator Nodes → Monitoring -
标注关键点:机器 ID 分配、序列号、时间戳。
-
图形化表达可让面试官快速理解你的设计。
3. 常见追问及回答
| 问题 | 回答思路 |
|---|---|
| 时钟回拨怎么办? | 使用逻辑时钟或阻塞等待,保证序列号唯一性 |
| ID 越界怎么办? | 增加时间戳位数或机器 ID 位数,结合业务规划 |
| 如何保证高并发性能? | 内存缓存批量生成 ID、异步分发、水平扩展节点 |
4. 面试展示要点
- 条理清晰:先需求,再方案,再架构,再实现。
- 权衡分析:能解释选择 Snowflake 或其他方案的理由。
- 细节展示:对时钟回拨、序列号溢出等细节能回答出来。
- 思路延展:可以提及 UUID、数据库自增 ID 或 ObjectId 等方案对比。
第七章:总结
设计全局唯一 ID 生成器,是系统设计面试中非常典型的题目,同时也是实际分布式系统中不可或缺的基础组件。通过本文,我们总结几个核心要点:
- 明确需求是关键
- 功能需求:唯一性、高并发、可扩展。
- 非功能需求:容错性、可监控性、可维护性。
- 选择合适的 ID 类型
- UUID:简单、全局唯一,但不易排序。
- 数据库自增 ID:易用、可排序,但单点瓶颈明显。
- Snowflake:分布式、高性能、可排序,最适合高并发分布式场景。
- 核心设计思路
- 拆分 ID 组成:时间戳 + 数据中心 ID + 机器 ID + 序列号。
- 保证分布式唯一性,处理时钟回拨和序列号溢出。
- 性能优化:批量生成、内存缓存、异步分发。
- 系统架构与实现
- 高可用:多机房部署、Leader 选举、容错策略。
- 扩展性:水平扩展、动态机器 ID 分配。
- 简化实现:单机 Snowflake 可快速验证思路,分布式方案适合生产环境。
- 面试答题技巧
- 梳理清晰逻辑:需求 → 方案 → 架构 → 实现 → 异常处理。
- 能够解释方案权衡与优化策略。
- 结合架构图和示例代码,让考官快速理解思路。
全局唯一 ID 生成器的设计,不只是生成数字,它体现了对分布式系统、高可用架构、性能优化和异常处理的综合能力。掌握这些思路,不仅能应对面试,也能指导实际业务系统的落地实现。



评论区