




文章摘要(AI生成)
本文讨论了订单系统设计的全过程,适用于技术面试中的系统设计题目。引言部分指出,订单系统是电商、支付等业务中的核心组件,因此设计时需从多个维度考虑。需求分析分为功能性和非功能性需求,涵盖用户下单、支付方式、订单状态流转等核心功能,还包括高并发支持、一致性、可扩展性等非功能要求。 随后,文章描述了核心架构设计,建议使用微服务或分层架构以实现灵活性和扩展性。数据库设计部分展现了核心实体、表设计、索引优化及并发控制等要素。核心流程如下单、支付、订单状态机等被详细设计,以确保系统的高可用性和安全性。 此外,技术实现要点如缓存策略、消息队列和事务处理,优化了系统在高并发环境下的表现。最后,文章探讨了如何进行扩展与优化,包括秒杀活动的特殊应对、多支付渠道的集成等内容,帮助面试者全面理解订单系统的设计与实现。
1. 引言
在技术面试中,系统设计题往往是最能体现候选人综合能力的环节。相比于单纯的算法或基础知识考察,系统设计更接近真实的工程实践,需要面试者从业务需求、系统架构、数据存储、性能优化、扩展性等多个维度进行思考和取舍。
其中,订单系统几乎是最常见的考点之一。原因很简单:
- 订单系统几乎存在于所有电商、支付、订票、外卖等业务场景中。
- 涉及到完整的流程:下单、支付、库存、发货、通知。
- 既要考虑功能正确性,又要考虑高并发、一致性和可扩展性。
本文将以“如何设计一个订单系统”为例,带你从零到一分析系统设计的完整过程。阅读完后,你不仅能应对面试题,还能在实际项目中举一反三。
2. 需求分析
在开始设计系统之前,最重要的一步是需求澄清。如果在面试中直接画架构图而不先确认需求,往往会被面试官认为缺乏系统思维。订单系统的需求可以分为两类:
2.1 功能性需求
- 用户下单:支持用户选择商品、数量并生成订单。
- 订单支付:支持多种支付方式(如支付宝、微信、PayPal)。
- 订单状态流转:
- 待支付 → 已支付 → 已发货 → 已完成
- 待支付 → 已取消(用户主动取消或超时未支付)
- 订单查询:支持用户查看自己的历史订单,按状态、时间等条件筛选。
- 订单更新:支付成功后更新状态,发货后更新物流信息。
2.2 非功能性需求
- 高并发支持:在大促或秒杀场景下能承受海量请求。
- 数据一致性:订单状态与支付、库存必须保持一致,避免超卖或漏单。
- 可扩展性:后续能方便接入新的支付渠道、促销逻辑、跨境业务。
- 容错与高可用:即使某些服务挂掉,核心下单链路也不能中断。
- 安全性:支付和订单数据必须保证传输和存储安全。
3. 核心架构设计
在明确需求后,下一步就是设计系统的整体架构。订单系统通常采用微服务架构或分层架构,以保证系统的灵活性和扩展性。
3.1 高层架构
从用户到后端的整体流程大致如下:
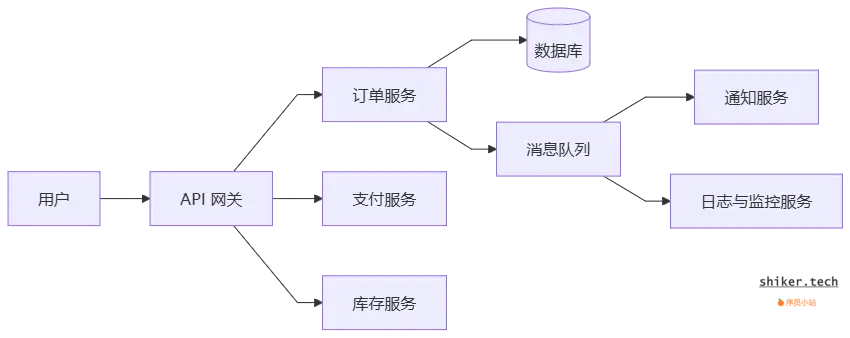
3.2 服务模块划分
- API 网关:统一入口,负责请求路由、鉴权、限流。
- 订单服务:核心模块,负责订单创建、状态流转、订单查询。
- 支付服务:与外部支付网关交互,处理支付回调。
- 库存服务:校验库存并执行库存预扣减。
- 通知服务:订单完成或状态变更后,通过短信/邮件/消息推送通知用户。
- 日志与监控服务:用于收集系统运行情况,提供故障排查能力。
- 消息队列:解耦服务,实现异步处理(如发货通知、消息推送)。
3.3 关键设计思路
- 解耦:通过消息队列减少服务之间的强依赖,提高系统稳定性。
- 弹性伸缩:订单服务、支付服务等模块都可以水平扩展。
- 一致性:通过分布式事务方案(TCC 或最终一致性)保证订单与支付、库存的数据正确性。
- 容错设计:即使支付或库存服务短暂不可用,订单服务仍然可以接受请求,并通过消息补偿机制恢复。
4. 数据库设计
数据库设计是订单系统的核心之一,既要满足功能查询,又要考虑并发写入、扩展性和一致性。下面给出推荐的核心表、ER 图、示例建表语句要点,以及针对高并发的优化方案。
4.1 核心实体与 ER 图(Mermaid)
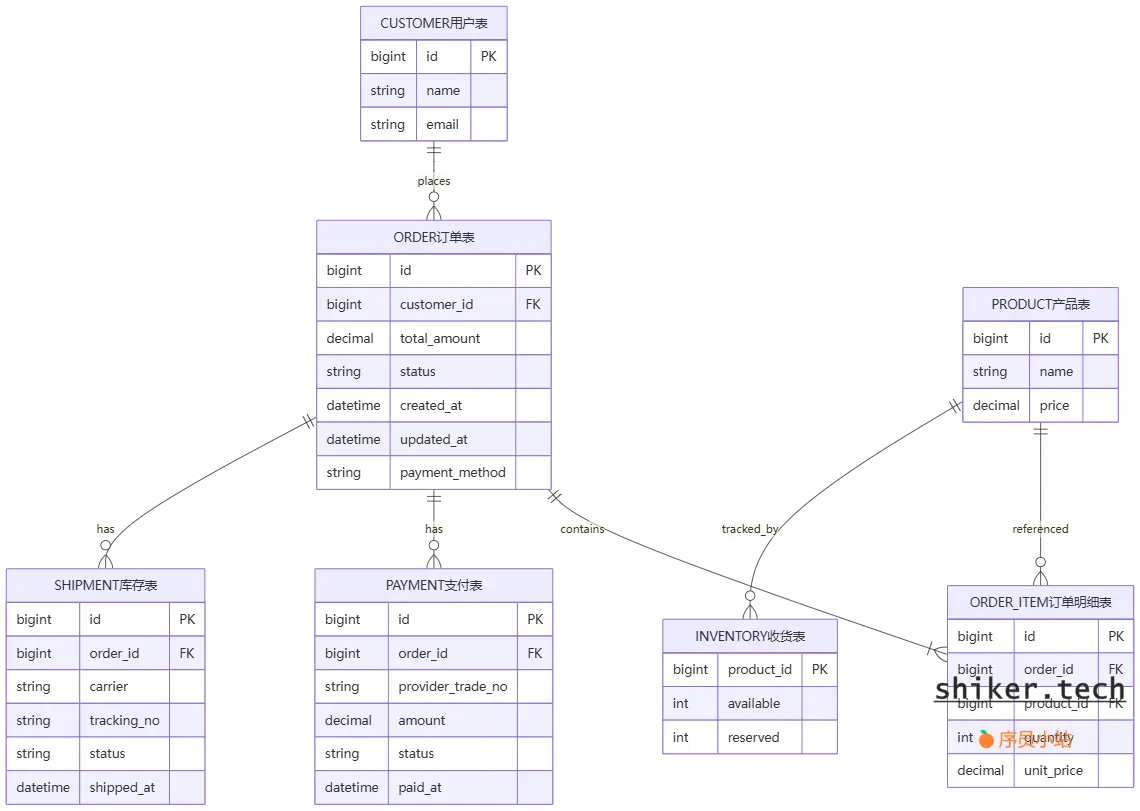
4.2 主要表设计要点(示例字段)
orders(订单主表)id:全局唯一(建议使用雪花ID/UUID)customer_id、total_amount、status(枚举)、payment_method、created_at、updated_at- 冗余字段(如
items_count、first_item_title)可加速列表展示
order_items(订单明细)order_id、product_id、quantity、unit_price、subtotal
payments(支付表)order_id、provider、provider_trade_no(防止重复回调幂等)、amount、status、paid_at
inventory(库存表)product_id、available、reserved(预扣库存用于秒杀/下单后锁库存)
shipments(收货/物流表)order_id、carrier、tracking_no、status、shipped_at
4.3 索引与查询优化建议
- 常用查询加索引:
orders(customer_id, created_at)、orders(status, created_at)、order_items(order_id) - 支付回调查重:在
payments(provider, provider_trade_no)上加唯一索引,保证幂等性。 - 使用覆盖索引(select 少量字段)提升查询速度。
- 使用分区(按时间 YYYYMM)或按
customer_id范围分片来管理历史数据与热数据。
4.4 事务与一致性策略
- 下单涉及
orders、order_items、inventory:- 推荐采用最终一致性 + 异步补偿(避免分布式强事务导致性能瓶颈)。
- 常见做法:先在数据库创建订单(状态
PENDING),在本地事务中预扣库存(或写入库存预扣记录),然后通过消息队列异步完成支付确认与后续补偿。
- 对于强一致性场景(如双重扣款风险、金钱转移),可考虑:
- 本地事务 + 两阶段提交(XA)(复杂、性能差)或
- TCC(Try-Confirm-Cancel) 模式(业务实现复杂但粒度可控)。
4.5 并发控制(防止超卖)
- 乐观锁:在
inventory表加version字段,更新时WHERE product_id=? AND version=?;适合冲突较少场景。 - 悲观锁:在高并发促销场景使用数据库行级锁或
SELECT ... FOR UPDATE(可能成为瓶颈)。 - 预减库存 + 消息队列回滚:下单时在缓存(Redis)预扣库存并写入订单 -> 支付/超时再确认或回滚;适合秒杀场景。
4.6 缓存、读扩展与归档
- 缓存(Redis):热点订单/商品详情缓存,减少 DB 读压。注意缓存失效与并发更新一致性问题(使用缓存穿透/击穿/雪崩防护策略)。
- 读写分离:主库写、只读从库分担查询压力,但注意读延迟带来的数据可见性问题(尤其是极短时间内紧接查询)。
- 历史数据归档:定期将 N 年以前的订单归档到冷库或对象存储以减小主库体量。
4.7 分库分表与分片策略
- 随着订单量增长,采用分库分表。常见策略:
- 按时间(按月/按年)分表,便于归档。
- 按用户
customer_id做 hash 分片,保证同一用户的订单落在同一分片,便于事务性查询。
- 注意索引设计与跨分片事务/查询的复杂性(尽量避免跨分片强事务)。
好的 👍 下面是 第五节:核心流程设计,这部分最能体现系统设计的思路。
5. 核心流程设计
订单系统的流程核心是下单 → 支付 → 发货 → 完成,在此过程中需要协调多个服务。
5.1 下单流程
- 用户选择商品,发起下单请求。
- 系统校验库存(库存服务)。
- 创建订单(状态
PENDING或待支付),写入数据库。 - 预扣库存(避免超卖,常见做法:Redis + DB 双写)。
- 返回订单号,等待用户支付。
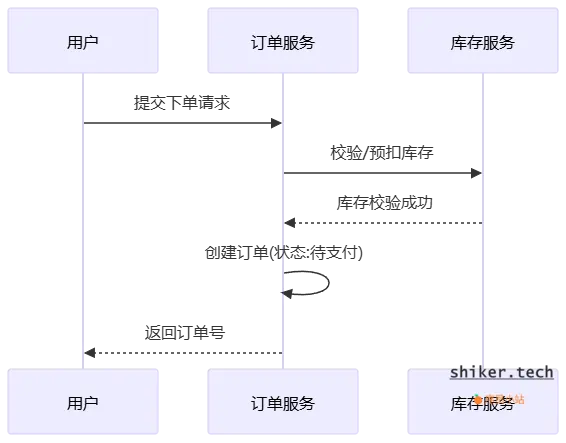
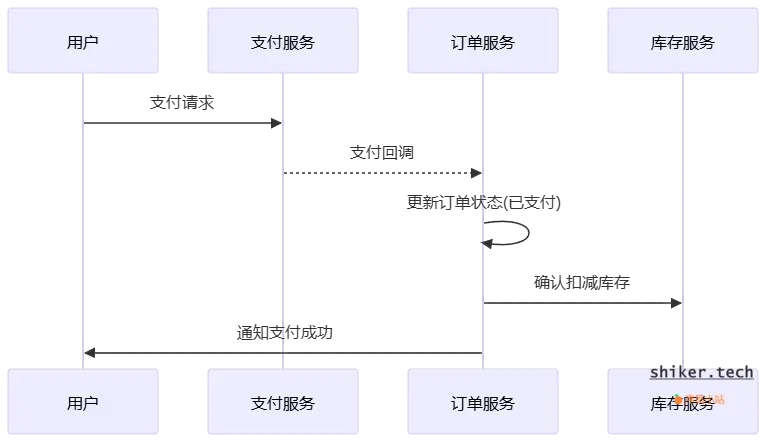
5.2 支付流程
- 用户选择支付渠道,跳转到第三方支付页面。
- 第三方支付完成后回调支付服务。
- 支付服务验证回调并更新支付记录。
- 订单服务更新订单状态为
已支付。 - 通知库存服务扣减库存(如果之前是预扣,则此时确认)。
- 推送支付成功消息给用户(短信/邮件)。
5.3 订单状态机
订单状态通常通过状态机来管理,避免逻辑分散。
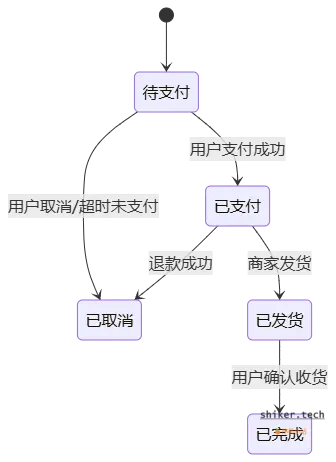
状态机的优势是:
- 避免非法状态流转(如
已完成 → 待支付)。 - 统一管理状态变化,便于扩展(如增加“部分发货”)。
5.4 取消订单 / 超时订单处理
- 用户主动取消:如果未支付,直接修改订单状态并释放库存。
- 系统超时取消:定时任务/延迟队列检测超过 15 分钟未支付的订单,自动取消并回滚库存。
- 支付已完成但用户取消:触发退款流程(依赖支付服务)。
5.5 幂等与异常处理
- 支付回调幂等:通过
provider_trade_no唯一索引保证不会重复更新订单。 - 消息重复消费:在 MQ 消费端加幂等校验(如 Redis 去重)。
- 异常补偿机制:如支付成功但订单状态未更新,可通过定时任务或补偿消息修复。
📌 在面试时,状态机图和流程图是加分项,能直观体现你对系统逻辑的把握。
6. 技术实现要点
6.1 缓存策略
- 目的:降低 DB 读压、加速热点数据访问(商品详情、最近订单列表等)。
- 缓存层次:
- 热点数据缓存(Redis):
GET product:{id}、GET user:{id}:orders:recent。 - 本地缓存(进程内 LRU)用于短期重复请求(避免重复 RPC)。
- 热点数据缓存(Redis):
- 缓存一致性:
- 读多写少:写操作成功后异步清缓存或直接删除 key(cache-aside)。
- 对于强一致性要求的数据(如订单状态变更的即时可见性)慎用缓存或短 TTL。
- 防护机制:
- 缓存穿透:对不存在 key 返回空对象并设置短 TTL 或布隆过滤器。
- 缓存击穿:对单个热点 key 使用互斥锁、请求排队或提前刷新。
- 缓存雪崩:给 key 随机 TTL 防止同一时间大面积失效。
6.2 消息队列 & 异步化
- 作用:削峰、解耦、异步处理(发送通知、日志、库存确认、搜索索引更新)。
- 常见用法:
- 支付成功后发出
order.paid事件,消费者有:通知服务、仓库/ERP、分拣系统、统计服务。 - 下单后发
order.created做后续处理(如风控、发券)。
- 支付成功后发出
- 消息属性:
- 消息要带上
order_id、trace_id、event_type、timestamp、idempotency_key。
- 消息要带上
- 幂等性:
- 消费端使用去重记录(Redis SET/DB 表)或设计幂等处理(更新 based on state)。
- 顺序性:
- 对于需要顺序处理的业务(状态流转),使用分区(同一个
order_id路由到同一分区/队列)或链式处理。
- 对于需要顺序处理的业务(状态流转),使用分区(同一个
6.3 事务处理与最终一致性
- 原则:尽量避免分布式强事务(XA)在高并发场景的使用;采用最终一致性 + 补偿更实用。
- 常用模式:
- Local Transaction + Outbox Pattern:在同一 DB 事务内写订单记录并写入 outbox 表,提交后由后台把 outbox 发到 MQ,保证事件不丢失且与 DB 原子性一致。
- Saga(基于补偿):将一个大事务拆成多个本地事务,若某一步失败,执行补偿动作回滚前面的步骤(如退款、回滚库存)。
- TCC(Try-Confirm-Cancel):对库存/资金类需要精确控制的操作,先 Try(预留资源),确认时 Confirm,失败时 Cancel。实现复杂但适用于金融级别场景。
- 示例:Outbox + MQ 流程(简述):
- 事务内:写
orders,写outbox(event: order.created)。 - 提交事务成功后:后台服务读取
outbox推送 MQ,标记为已发送。 - 消费方收到后处理并反馈,保障最终一致性。
- 事务内:写
6.4 接口设计(REST 示例)
- 设计要点:幂等、明确的状态码、分页/过滤、版本化。
- 示例:
POST /v1/orders— 创建订单(请求体包含 items、payment_method、shipping_info),返回202 Accepted+order_id(若异步处理)或201 Created。GET /v1/orders/{order_id}— 查询订单详情。POST /v1/orders/{order_id}/pay— 发起支付(返回支付跳转 URL 或支付渠道请求)。POST /v1/payments/callback— 支付回调(必须幂等)。
- 幂等实现:对创建类接口支持
Idempotency-Keyheader;服务端记录 key 与对应结果,重复请求返回相同结果。
6.5 高并发场景优化
- 限流与熔断:
- 在 API 网关层做请求限流(固定窗口/漏桶/令牌桶),保护下游服务。
- 熔断器(如
Hystrix / Resilience4j)用于快速失败,避免级联故障。
- 削峰策略:
- 前端排队页面、令牌发放、延迟队列等。
- 进一步优化库存处理(秒杀):
- 先在 Redis 做原子性
DECR,当 Redis 成功再写入 DB(异步确认);若 DB 写入失败则补偿 Redis。 - 使用布隆过滤器和本地预热降低请求到 DB 的比例。
- 先在 Redis 做原子性
- 数据库层面:
- 分库分表 + 垂直拆分(热表写在独立库)。
- 批量写入、合并更新(减少事务次数)。
- 读写分离注意:读延迟可能导致支付之后马上读取不到最新状态,设计上要考虑短时可见性不一致(或在关键路径读主库)。
6.6 安全与合规
- 支付安全:
- 使用 HTTPS、签名验证(回调验签)、回调 IP 白名单 / 时间戳+签名。
- 数据保护:
- 敏感数据加密存储(如用户支付信息)、最小化日志中敏感字段。
- 审计日志:
- 对关键操作记录审计链(who/when/what),便于回溯。
6.7 可观测性(监控、日志、分布式追踪)
- 日志:结构化日志(JSON),包含
trace_id/span_id,便于聚合和搜索。 - 指标(Prometheus 风格):
- QPS、错误率、平均延迟、下单成功率、库存失败率、支付成功率。
- 告警:结合 SLO 设置告警阈值(如支付成功率低于 X%)。
- 分布式追踪:使用
OpenTelemetry / Jaeger追踪请求链路,快速定位慢点或失败点。 - 事后修复工具:提供订单补偿操作台(手动触发补偿、重发 MQ、人工修复状态)。
6.8 测试 & 灰度发布
- 自动化测试:
- 单元测试、集成测试(包含 MQ、DB 的集成测试)、契约测试(Consumer-Driven Contract)。
- 压测:
- 模拟真实流量(支付回调、并发下单、秒杀场景),发现瓶颈(DB、网络、GC)。
- 灰度发布:
- Canary 发布、流量切分、影子流量测试(不影响线上用户)用于验证新特性/DB 变更。
- 混沌工程:
- 在非关键时段进行网络抖动/服务故障实验,验证补偿与恢复策略。
6.9 示例代码片段(伪代码:创建订单 + Outbox)
// 伪代码说明:在一个本地事务中写订单与 outbox
@Transactional
public OrderResponse createOrder(CreateOrderReq req) {
Order order = orderRepo.insert(buildOrder(req)); // orders 表
OutboxEvent ev = new OutboxEvent(order.getId(), "order.created", payload);
outboxRepo.insert(ev); // 同一事务内写入 outbox
return new OrderResponse(order.getId());
}
// 事务提交后:后台线程读取 outbox 并发送到 MQ(至少一次)
public void dispatchOutbox() {
List<OutboxEvent> events = outboxRepo.findPending();
for (OutboxEvent e : events) {
mq.send(e);
outboxRepo.markSent(e);
}
}
7. 扩展与优化
在系统稳定运行之后,面临的主要任务是:应对更高的并发、更复杂的业务(多渠道/跨境/多租户)、提升可观测性并在成本与性能间做权衡。下面按场景逐项展开。
7.1 秒杀 / 大促专项(防超卖与削峰)
目标:在极高并发下保证库存不超卖、系统稳定且响应可接受。
常用做法(组合使用)
- 限流 + 令牌发放:在 API 网关做全局和分布式限流(漏桶/令牌桶),对秒杀活动发放有限令牌(可以预分配给用户或按速率发放)。
- 预热与白名单:预热缓存、提前发放抢购资格给会员或付费用户。
- Redis 原子预扣 + Lua 脚本:在 Redis 端做原子
DECR或DECRBY,返回成功的客户端才允许进入下单流程。 - 异步下单(先占位,后写库):成功拿到 Redis 令牌后,将请求放入队列/任务流;消费者按速率写 DB(避免大量并发写库)。
- 延迟队列与超时补偿:订单支付超时未完成,使用延迟队列自动回滚 Redis 预扣或释放令牌。
- 本地排队与分区处理:把请求按商品分区路由到固定分区队列,保证单商品的顺序性并降低锁争用。
秒杀流程
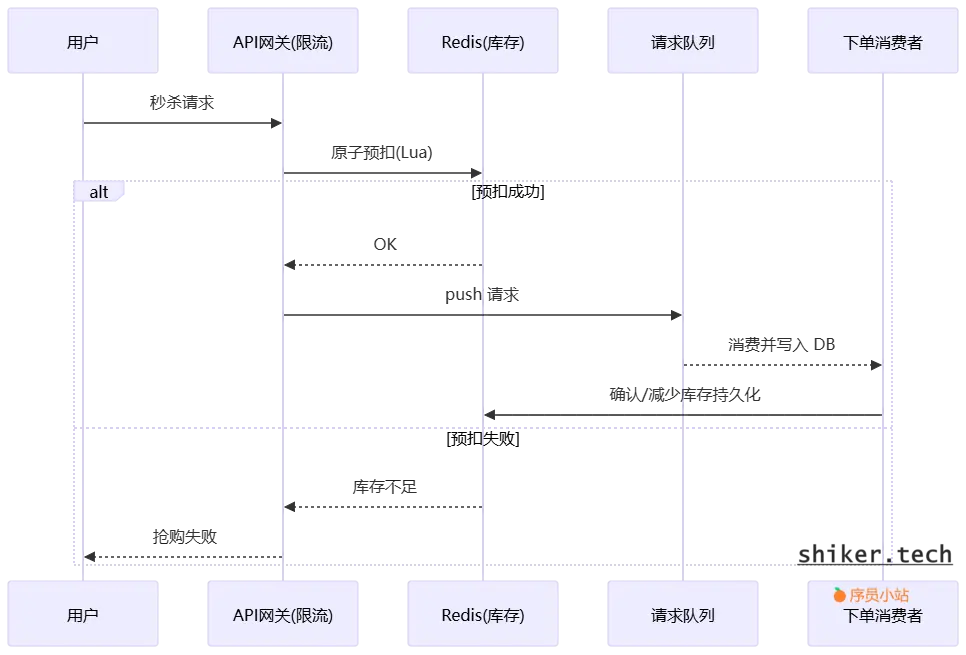
实现细节
- Redis Lua 脚本保证原子性(检查库存并
decr)。 - 下单消费者要做幂等(基于
userId+activityId或orderToken去重)。 - 使用“预占 + 异步确认”会出现极短时间的“幻读”或一致性窗口,需在业务上容忍或通过短期锁/主库读取解决。
面试要点(快速说明)
- 先说“前端限流 + Redis 原子预扣 + 异步入库 + 延迟队列回滚”这条路线;然后说明每步的权衡(延迟 vs 一致性 vs 成本)。
7.2 多支付渠道接入(可扩展、幂等、安全)
目标:优雅接入多个支付渠道(支付宝、微信、PayPal、Stripe 等),并保证支付回调的幂等与安全。
架构与模式
- Payment Adapter(适配器)模式:对每个支付渠道实现统一接口(
createPayment,verifyCallback,refund),上层业务只调用抽象接口。 - 回调幂等:在
payments表上对provider + provider_trade_no建唯一索引;回调处理先检查是否已处理,已处理直接返回成功。 - 安全验签:回调必须校验签名/证书/时间戳,防止伪造。
- 异步确认:有些通道可能只返回异步通知,建议把回调写入队列,由专门的支付处理服务消费并更新订单(便于重试与补偿)。
适配器示意
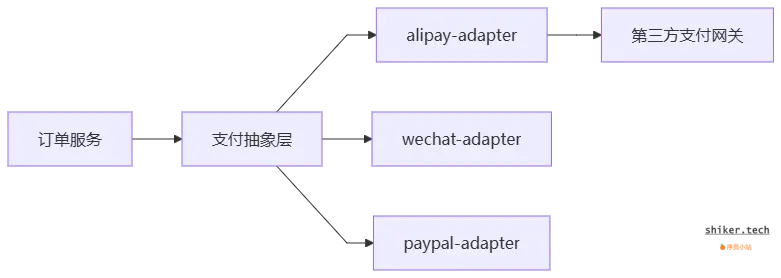
测试与对账
- 使用沙箱环境、模拟回调、并做每日对账(payments 与第三方结算单对账)。
- 设计退款/撤销链路(幂等且可追踪)。
面试要点
- 提到
Idempotency-Key、唯一约束和回调验签,以及 outbox 异步写入 MQ 的做法作为可靠性保障。
7.3 多租户 & 跨境支持
目标:支持不同商家/租户或跨境业务(多币种、税务、时区、合规)。
多租户策略
- 隔离程度选择:
- 单库多租户(schema/tenant_id 列):实现简单,成本低,但安全与扩展受限。
- 多库多租户(每租户独立 DB):隔离性强,便于单租户迁移/分表,但资源成本高。
- 混合:小租户共库,大租户独立库。
- 配置管理:为每租户存储配置(支付渠道、税率、发票规则、品牌设置)。
- 鉴权/路由:请求带
tenant_id,网关/路由层据此路由到对应服务/DB。
跨境注意点
- 多币种:价格与清算要支持不同货币,建议保留 订单金额(显示币种) 与 结算币种(本位) 两套字段,并记录汇率快照。
- 税费与合规:根据国家/地区计算税费、VAT/GST;保存税务凭证以便发票与审计。
- 时区 & 本地化:所有时间戳统一存 UTC,展示时根据用户时区转换;文案与货币格式本地化。
- 法规与支付限制:注意跨境支付合规、反洗钱(KYC)需求、隐私法(如 GDPR)。
面试要点
- 说清“隔离策略的权衡(成本 vs 安全)”并举例:大客户独立库,小客户共享库。
7.4 可观测性与 SLO 实践
目标:在复杂分布式系统中,快速定位问题并保证业务可用性。
关键维度
- 日志:结构化日志(JSON),包含
trace_id、span_id、order_id、user_id、tenant_id。 - 指标(Metrics):下单成功率、支付成功率、库存失败率、订单处理延迟、MQ 消费延迟、DB 连接数等(Prometheus)。
- 追踪(Tracing):
OpenTelemetry/Jaeger/skywalking用于跨服务追踪请求链路,定位慢调用/错误。 - 告警与 SLOs:
- 定义 SLO(如下单成功率 99.9%/月,支付回调处理 99.95%)。
- 告警包含演进策略(阈值、抖动、自动恢复动作)。
- 操作台 & 修复工具:提供人工补偿(重试 MQ、手动修改订单状态)、对账工具与异常单列表。
面试要点
- 举例某个指标触发时的排查步骤:从错误率 -> trace -> logs -> downstream 服务,说明
trace_id的作用。
7.5 弹性扩展(Scalability & Resilience)
服务层
- 保持服务 无状态(状态放 Redis/DB),方便水平扩容与滚动更新。
- 使用容器化 + 自动伸缩(
Kubernetes HPA/Cluster Autoscaler),并在伸缩时做平滑限流。 - 连接池与资源限制:严格配置 DB/Redis 连接池,避免因池满导致级联失败。
数据库层
- 读写分离、分库分表、垂直拆分 为常用扩展手段。
- 使用中间件(
ShardingSphere、Vitess等)或应用层路由。 - 对热表采取异步批处理、冷归档策略减少主库压力。
降级与熔断
- 对非关键路径(统计、推荐)进行降级;对关键路径用熔断器快速失败并返回友好降级结果。
- 对外部依赖(第三方支付、物流)做超时限制与重试策略(指数退避)。
面试要点
- 强调“先做服务无状态化和限流,再做分库分表”的顺序,以体现工程实践的优先级。
7.6 性能优化 & 成本权衡
缓存 vs 一致性
- 缓存能极大降低读成本,但会带来一致性复杂度:对于订单这类敏感数据,慎用缓存或采用短 TTL + 主库关键路径读取。
批量化 - 批量写入、合并更新可以显著降低 IOPS、事务次数(统计、日志、索引更新等适用)。
延迟容忍设计 - 把非关键的工作异步化(邮件、统计、搜索索引)以减少响应延迟。
成本控制 - 根据访问热度分层存储(热数据放高性能实例,冷数据归档到廉价对象存储)。
- 在云上利用预留实例、按需
autoscale策略平衡成本与弹性。
面试要点
- 在回答中给出一个具体优化思路(例如把订单列表读压力降低 70% 的方案:加 Redis 缓存+短 TTL+后台异步刷新),并说明可能的问题(缓存穿透、失效窗口)。
7.7 安全、合规与运维策略
- 敏感数据保护:卡号/令牌不在系统中明文存储;使用 PCI-DSS 合规的第三方支付管道。
- 审计与权限:关键操作(退款、人工改单)要有审计记录并限制权限。
- 备份与恢复:定期快照、异地备份及演练恢复流程(RTO/RPO 指标)。
- 灾备(DR):跨可用区/区域部署关键服务,考虑流量切换策略。
7.8 面试中的回答模板
- 先说“我会根据业务场景选择优化策略”,举秒杀场景的核心要点(限流、Redis 预扣、异步下单、延迟补偿)。
- 说明多支付接入的工程实践(适配器、回调幂等、验签、对账)。
- 说明多租户/跨境的隔离与合规策略(单库 vs 多库、税务与汇率处理)。
- 简短提及可观测性与 SLO,并列出 2–3 个关键指标(下单成功率、支付成功率、下单延迟)。
- 最后给出权衡结论(例如:为了性能我会先做缓存和异步化;为了一致性在支付/资金路径使用更严格策略)。
8. 总结与答题技巧
订单系统是系统设计面试中最常见的题目之一。它覆盖了功能设计、数据库建模、分布式架构、高并发处理、支付与库存一致性等多个方面。面试官往往通过此题考察候选人的 系统性思考能力 与 工程落地经验。
下面我们来总结要点,并给出答题时的组织方式。
8.1 全局回顾
- 需求分析:明确功能需求(下单、支付、发货、退款)、非功能需求(高可用、高并发、一致性)。
- 数据模型:订单表、订单项表、支付表、库存表,考虑分库分表与幂等。
- 核心流程:订单从创建 → 支付 → 发货 → 收货 → 完成/退款,全链路要有状态机。
- 系统架构:分层设计 + 微服务拆分(订单、支付、库存、物流、用户服务)。
- 一致性保证:本地事务、分布式事务(TCC、消息最终一致)、补偿机制。
- 高并发优化:缓存、消息队列、读写分离、限流降级。
- 扩展优化:支持秒杀大促、多支付、多租户跨境、可观测性、弹性扩展。
8.2 答题技巧
在面试中,你可以按照以下结构来组织回答:
- 开篇框架
- “我会先从需求分析入手,再介绍数据建模和系统架构,最后说明高并发和一致性处理,以及一些扩展优化点。”
- 这样能让面试官知道你有清晰的结构,而不是想到哪说到哪。
- 逐层展开
- 用 “场景 + 方案 + 取舍” 的模式:
- 场景:订单系统高并发下单。
- 方案:Redis 原子扣减库存 + MQ 异步下单。
- 取舍:一致性延迟 vs 性能。
- 用 “场景 + 方案 + 取舍” 的模式:
- 突出关键挑战
- 强调“支付与库存”这种资金敏感路径的一致性。
- 提及“幂等、补偿、对账”来表现工程经验。
- 点到为止的扩展
- 不要一口气讲所有细节,可以在回答基础架构后,加一句“如果时间允许,我还可以展开介绍秒杀场景的优化”。
- 这会引导面试官继续追问你擅长的领域。
8.3 常见加分点
- 图示表达:能在白板或纸上画出系统交互流程/架构图。
- 结合经验:提到自己在项目中遇到过的类似问题(例如支付回调重复、库存超卖),说明如何解决。
- 平衡意识:面试官很看重候选人是否能权衡一致性 vs 可用性 vs 成本。



评论区