




文章摘要(AI生成)
批量处理数据的技术,适用于处理静态的数据集而非连续不断的数据流。批处理通常用于需要离线分析和处理大规模数据的场景,例如数据清洗、ETL(Extract, Transform, Load)过程、数据仓库构建等。批处理的主要特点包括按批次处理数据、高效利用计算资源、适用于离线场景等。常见的批处理框架和工具包括Apache Hadoop、Apache Spark、Apache Hive等。批处理的应用场景包括数据仓库构建、报表生成、离线数据分析等。与流处理相比,批处理通常具有较高的处理延迟,但适用于对历史数据进行分析和决策。在实际应用中,流处理和批处理技术常常结合使用,以满足不同的数据处理需求。
什么是流处理
流处理(Stream Processing)是一种实时处理数据流的技术,旨在处理和分析连续不断的数据流,而不是处理静态的批量数据。流处理通常用于需要实时反应和决策的应用场景,例如金融交易监控、实时日志分析、传感器数据处理、网络监控和在线广告投放等。
流处理概念
数据源:接收和存储实时数据流。
数据接收器:持续从数据源接收数据流,并传递给处理引擎。
处理引擎:执行流数据的处理操作,支持有状态的流处理和事件时间处理。
数据处理组件:对数据流进行各种操作和变换
状态管理:维护和管理流处理中的有状态操作,确保数据一致性和容错性。
时间管理:基于事件时间、处理时间或摄取时间进行数据处理
容错机制:通过检查点和重放机制来确保在故障时能够恢复数据处理。
数据输出:将处理后的数据输出到目标存储系统或服务中。
示意:
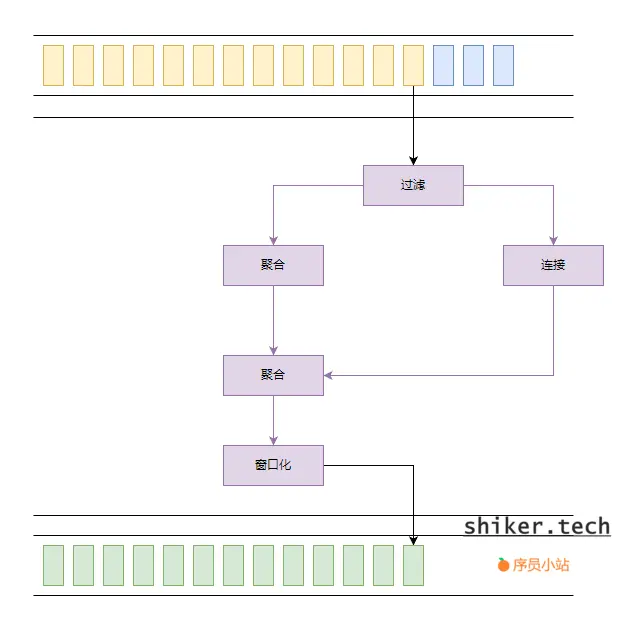
流处理的主要特点
- 实时性:流处理系统可以实时处理和响应数据流中的事件,通常具有较低的延迟。
- 连续性:数据流是连续不断的,流处理系统需要能够长时间持续运行,处理无穷无尽的数据。
- 弹性和扩展性:流处理系统通常需要具备良好的扩展性,可以根据数据流量的变化动态调整处理资源。
- 高可用性:为了保证数据处理的连续性和可靠性,流处理系统需要具备高可用性,能够在部分节点故障时继续运行。
流处理的常见框架和工具
- Apache Kafka:一种分布式流处理平台,主要用于构建实时数据管道和流处理应用。
- Apache Flink:一种流处理框架,支持有状态的计算,可以用于复杂的事件处理和数据分析。
- Apache Spark Streaming:Spark的扩展模块,支持实时数据流处理,结合了批处理和流处理的优点。
- Apache Storm:一种分布式实时计算系统,适用于低延迟的数据流处理。
流处理的应用场景
- 金融交易监控:实时监控和分析金融市场中的交易数据,检测异常交易行为。
- 实时日志分析:收集和分析服务器日志,及时发现和解决系统问题。
- 物联网(IoT)数据处理:处理来自传感器和设备的数据流,进行实时监测和控制。
- 在线广告投放:根据用户的实时行为数据,动态调整广告投放策略。
- 社交媒体分析:实时分析社交媒体平台上的用户行为和内容,获取用户兴趣和热点话题。
流处理技术在现代数据驱动的应用中扮演着越来越重要的角色,能够帮助企业和组织在第一时间获取和处理关键数据,做出及时的决策。
什么是批处理
批处理(Batch Processing)是一种一次性处理大量数据的计算方法,通常用于需要处理大量数据但对实时性要求不高的场景。批处理系统会在预定的时间或特定条件下启动,处理积累的数据,并在处理完成后生成结果。
批处理主要概念
- 数据源:存储待处理的批量数据。
- 任务调度器:定时或根据特定条件启动批处理任务。
- 数据读取组件:从数据源中批量读取数据,并行读取以提高效率。
- 处理引擎:执行批量数据的处理操作,支持大规模数据的并行处理。
- 数据处理组件:对批量数据进行各种操作和变换,如Map、Filter、GroupBy、Join、Aggregation、Sort、Reduce等。
- 工作流管理:定义和管理数据处理任务的依赖关系和执行顺序,支持任务重试。
- 容错机制:通过数据检查点和任务重启来确保在故障时能够恢复数据处理。
- 数据输出:将处理后的数据输出到目标存储系统或服务中。
示意:
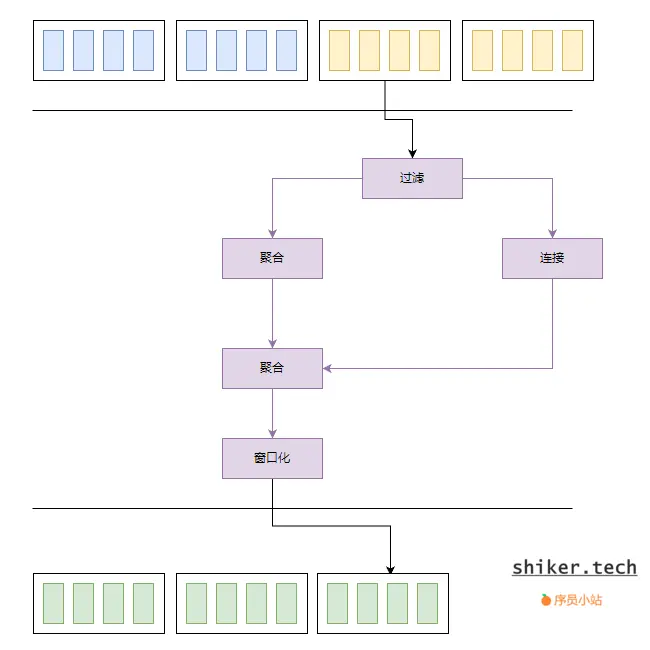
批处理的主要特点
- 大量数据处理:批处理系统适合处理大规模的数据集,可以一次性处理数百万、数亿甚至更多的数据记录。
- 定期执行:批处理任务通常按照预定的时间间隔(如每天、每周)或在特定条件满足时执行。
- 高吞吐量:批处理系统设计的目标是高吞吐量,即在单位时间内处理尽可能多的数据。
- 容错性:批处理系统通常具有很强的容错能力,可以在处理过程中应对部分节点故障或数据损坏。
批处理的常见框架和工具
- Apache Hadoop:一个分布式处理框架,使用MapReduce编程模型来处理大规模数据集。
- Apache Spark:一个统一的分析引擎,支持批处理、流处理和图计算等多种计算模型。
- Apache Flink:虽然主要用于流处理,但也支持批处理任务。
- Google BigQuery:一种完全托管的数据仓库服务,支持大规模数据的批处理查询。
- AWS Batch:Amazon Web Services提供的批处理服务,用于在云中运行大规模批处理作业。
批处理的应用场景
- 数据仓库加载:定期将业务系统中的数据导入数据仓库,以支持后续的数据分析和报表生成。
- ETL(Extract, Transform, Load):从多个数据源提取数据,进行清洗和转换,然后加载到目标数据库或数据仓库中。
- 日志处理:收集和处理服务器日志、应用日志等,以进行离线分析和报告生成。
- 定期报表生成:根据定期收集的数据生成业务报表和统计数据。
- 批量数据迁移:将大量数据从一个系统迁移到另一个系统,通常在数据量较大且需要一次性完成的情况下使用。
批处理与流处理的对比
| 特性 | 批处理 | 流处理 |
|---|---|---|
| 数据处理方式 | 一次性处理大量数据 | 实时处理连续数据流 |
| 处理时间 | 定期执行,处理时间较长 | 实时执行,处理时间较短 |
| 数据流特性 | 静态数据,处理前数据是固定的 | 动态数据,数据持续不断地流入 |
| 适用场景 | 数据仓库加载、ETL、报表生成 | 实时监控、实时分析、在线处理 |
| 处理框架 | Hadoop、Spark、AWS Batch等 | Kafka、Flink、Spark Streaming等 |
批处理在大规模数据处理和离线分析中具有重要作用,而流处理则在需要实时响应和低延迟的应用中表现出色。两者可以根据具体应用场景的需求进行选择和组合。



评论区