




文章摘要(AI生成)
全文检索是一种用于在文本文档或记录集合中进行快速搜索的技术。全文检索包括建立索引、搜索查询、评分和语言处理等步骤,能够让用户按照关键字或查询来查找文档。全文检索与全文查找有所不同,全文检索更为复杂、全面,而全文查找更为简单直接。在实现全文索引方面,MySQL和MongoDB分别有着不同的方式。MySQL通过创建全文索引并执行 MATCH ... AGAINST 查询实现全文搜索,而MongoDB则通过创建文本索引并使用 $text 操作符进行检索。此外,MySQL的倒排索引技术在复杂场景下存在一些局限性,需要根据具体情况进行使用和优化。对于MongoDB,虽然不直接支持中文全文检索,但可以通过结合中文分词器实现。综合来看,在不同数据库中,全文检索的实现方式和技术应用存在差异,需要根据具体情况选择适合的方法。
全文检索是一种用于在文本文档或记录集合中进行快速搜索的技术。它旨在让用户能够按照其关键字或查询来查找文档、文章、记录或其他文本数据。
全文检索通常涉及以下几个方面:
- 建立索引:全文检索引擎会对文本数据建立索引,以便能够快速地检索文档。这些索引可以包括单词、短语或其他文本单位的位置和频率信息。
- 搜索查询:用户可以使用关键字、短语或其他查询条件来搜索文本数据。搜索引擎会根据查询条件查找匹配的文档,并返回结果。
- 评分:在某些全文检索系统中,检索结果可能会根据文档与查询之间的匹配程度进行评分,以便将最相关的文档排在前面。
- 语言处理:全文检索系统可能会应用语言处理技术,如词干提取、同义词扩展等,以提高检索的准确性和覆盖范围。
全文查找和检索的差异
一些同学可能会认为mysql也能实现全文检索,这种说法便是混淆了全文检索与全文查找的定义:
- 全文检索:通常用于描述一种更广泛的技术和系统,包括建立索引、执行查询、评分等功能。全文检索可能涉及到对文本数据进行索引、语言处理和相关性评分等步骤,以提供更丰富和更复杂的搜索功能。
- 全文查找:有时可能用于描述更简单、直接的文本搜索操作,可能不涉及到复杂的索引、评分或语言处理技术。全文查找可能更侧重于基本的搜索功能,例如简单地查找文档中是否包含特定的关键字或短语。
我们通过下面一个用例便能知道两者区别:
我们假设有一段文本:
Spring 灵活的库受到全世界开发人员的信赖。 Spring 每天为数百万最终用户提供令人愉悦的体验 - 无论是流媒体电视,网上购物,或无数其他创新解决方案。 Spring 还得到了所有科技巨头的贡献,包括阿里巴巴、亚马逊、谷歌、微软等。
我们想要查找“科技巨头”时,使用mysql语句:
select * from table where text like "%科技巨头%"
这就会通过遍历进行顺序查找:

但是,假如我们使用es、solr这种检索时,其会通过分词将我们的查找方式变为:
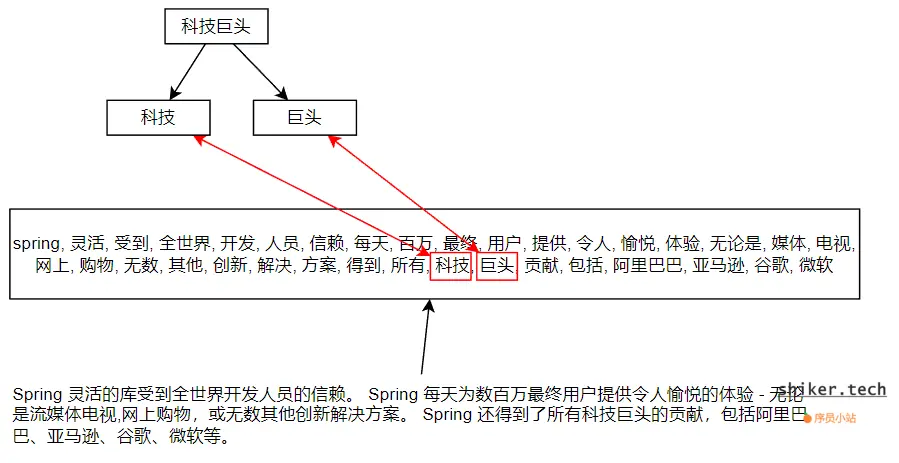
这两种查找思想,一种是通过关键词在原文中一行一行比较,一种是提取原文关键词,通过关键词匹配确定是否能够命中文档。
全文检索的几种实现方式
MySql全文索引
-
创建全文索引:首先,需要在需要进行文本搜索的表的一个或多个文本列上创建全文索引。只有具有全文索引的列才能进行全文搜索。例如,如果要在
content列上进行全文搜索,可以使用以下命令创建全文索引:ALTER TABLE your_table_name ADD FULLTEXT INDEX idx_content (content); -
执行全文搜索:一旦创建了全文索引,就可以使用
MATCH ... AGAINST来执行全文搜索。这个语法允许您指定要搜索的列、搜索的关键字或短语以及其他选项。SELECT * FROM your_table_name WHERE MATCH(content) AGAINST('your_search_keyword');在这个查询中,
content是您想要搜索的列,'your_search_keyword'是您要搜索的关键字或短语。 -
添加条件:您可以通过在
WHERE子句中添加其他条件来进一步筛选搜索结果。例如,假设有一个名为articles的表,其中包含title和body列,可以按照以下方式进行全文搜索:SELECT * FROM articles WHERE MATCH(title, body) AGAINST('your_search_keyword');这将返回包含搜索关键字的标题或正文的所有文章。请注意,全文搜索不区分大小写,并且默认情况下会忽略常见的停用词(如“a”,“and”,“the”等)。
虽然MySQL数据库也支持倒排索引,但目前较少人使用,主要是因为该技术有一些局限性和缺陷。
首先,MySQL的倒排索引只支持单表和简单查询场景。如果涉及到多表关联查询,或者复杂的搜索逻辑,就无法使用倒排索引。此时,需要通过联合查询、文本搜索引擎等其它技术来完成。因此,对于复杂场景,MySQL的倒排索引并不能很好地解决问题。
其次,MySQL的倒排索引性能有一定限制。在数据量较大、写操作较频繁、并发性要求较高的情况下,倒排索引可能会影响整个数据库的性能。这主要是因为倒排索引需要额外的存储空间和计算资源来维护,会占用大量的系统资源。因此,需要根据具体的场景来进行评估和选择,避免在性能上出现瓶颈。
综上所述,MySQL的倒排索引技术并非完全无用,但需要根据具体的场景来进行使用和优化,以充分发挥其优势。在特定的场景下,结合MySQL的倒排索引,可以有效地提高搜索效率,提升用户体验。
MongoDb全文索引
-
创建文本索引:首先,在需要进行全文检索的集合上创建一个文本索引。文本索引可以针对一个或多个文档字段创建。例如,如果要在
content字段上进行全文检索,可以执行以下命令创建文本索引:db.collection.createIndex({ content: "text" }) -
执行文本搜索:一旦创建了文本索引,就可以使用
$text操作符执行全文检索。可以将$text操作符与$search操作符一起使用,以指定要搜索的关键字或短语。例如:db.collection.find({ $text: { $search: "your_search_keyword" } })在这个查询中,
your_search_keyword是您要搜索的关键字或短语。 -
获取匹配结果:执行文本搜索后,MongoDB 将返回匹配的文档,这些文档根据其与搜索查询的匹配程度进行排序。
mongodb是不支持中文全文检索的(文本搜索语言),因此我们可以通过mongo+中文分词器实现全文检索,即在创建创建文档时对所需文本字段进行分词(以Ansj分词器为例):
private List<String> getKeyWordsByContent(String content) {
StopRecognition filter = new StopRecognition();
//停用词配置
filter.insertStopNatures("w");
filter.insertStopNatures("x");
filter.insertStopNatures("x");
filter.insertStopNatures("null");
filter.insertStopRegexes("[\\p{P}\\p{N}\\p{L}]");
filter.insertStopRegexes("[-]+");
List<String> keywords =
IndexAnalysis.parse(content).recognition(filter).getTerms().stream().map(Term::getName).distinct()
.collect(Collectors.toList());
return keywords;
}
然后对分词后的keywords添加全文索引即可。
Elastic全文检索
-
准备数据:
首先,您需要准备要搜索的文档数据,并将其存储在 Elasticsearch 中。文档可以是 JSON 格式的结构化数据,可以包含任意数量的字段和文本内容。
-
创建索引:
在将数据存储在 Elasticsearch 中之前,您需要定义一个索引。索引是文档的逻辑容器,它允许您对文档进行分组并定义一组搜索和分析的设置。您可以使用 Elasticsearch 的索引 API 来创建索引,创建完成后连接es。
RestHighLevelClient client = new RestHighLevelClient( RestClient.builder(new HttpHost("localhost", 9200, "http"))); -
插入文档:
一旦索引创建好了,您就可以将文档插入到 Elasticsearch 中。您可以使用 Elasticsearch 的文档 API 将文档插入到指定的索引中。
IndexRequest request = new IndexRequest(indexName) .id("1") .source(Map.of( "title", "Elasticsearch 入门指南", "content", "Elasticsearch 是一个基于 Lucene 的开源搜索引擎", "author", "John Doe" )); client.index(request); -
执行全文搜索:
当数据插入到 Elasticsearch 中后,您可以使用 Elasticsearch 的查询 API 来执行全文搜索。Elasticsearch 提供了丰富的查询 DSL(Domain Specific Language),您可以使用各种查询来搜索文档。
// 执行全文搜索 SearchRequest searchRequest = new SearchRequest(indexName); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); searchSourceBuilder.query(QueryBuilders.matchQuery("content", "搜索引擎")); searchRequest.source(searchSourceBuilder); SearchResponse searchResponse = client.search(searchRequest); -
处理搜索结果:
执行搜索后,Elasticsearch 将返回与搜索条件匹配的文档。您可以根据需要对搜索结果进行排序、过滤、聚合等操作,以满足具体的业务需求。
//处理搜索结果 for (SearchHit hit : searchResponse.getHits().getHits()) { System.out.println(hit.getSourceAsString()); }



评论区