




文章摘要(AI生成)
分治法是一种算法设计策略,将一个大问题分解为多个相同的子问题,递归地解决这些子问题,然后将结果合并得到原问题的解。分治法适用于问题具有规模缩小容易解决、可以分解为小问题且具有最优子结构性质、子问题解可合并为原问题解、子问题相互独立的情况。算法步骤包括分解、解决和合并。常见应用有二分搜索、归并排序、快速排序、大整数乘法等。以二分搜索为例,通过每次取中点比较大小,逐渐缩小查找范围,时间复杂度为O(logn)。另外,以寻找两个正序数组中的中位数为例,通过比较两个数组中的中位数来确定中位数所在位置,时间复杂度要求为O(log(m+n))。
分治法
基本思想及策略
分治法的设计思想是:将一个难以直接解决的大问题,分割成一些规模较小的相同问题,以便各个击破,分而治之。
分治策略是:对于一个规模为n的问题,若该问题可以容易地解决(比如说规模n较小)则直接解决,否则将其分解为k个规模较小的子问题,这些子问题互相独立且与原问题形式相同,递归地解这些子问题,然后将各子问题的解合并得到原问题的解。这种算法设计策略叫做分治法。
分治法适用的情况
分治法所能解决的问题一般具有以下几个特征:
1) 该问题的规模缩小到一定的程度就可以容易地解决
2) 该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质。
3) 利用该问题分解出的子问题的解可以合并为该问题的解;
4) 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子子问题。
基本步骤
分治法在每一层递归上都有三个步骤:
step1 分解:将原问题分解为若干个规模较小,相互独立,与原问题形式相同的子问题;
step2 解决:若子问题规模较小而容易被解决则直接解,否则递归地解各个子问题
step3 合并:将各个子问题的解合并为原问题的解。
它的一般的算法设计模式如下:
Divide-and-Conquer(P)
1. if |P|≤n0
2. then return(ADHOC(P))
3. 将P分解为较小的子问题 P1 ,P2 ,...,Pk
4. for i←1 to k
5. do yi ← Divide-and-Conquer(Pi) △ 递归解决Pi
6. T ← MERGE(y1,y2,...,yk) △ 合并子问题
7. return(T)
常用问题
二分搜索,归并排序,快速排序,大整数乘法
二分查找
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
输入: nums = [-1,0,3,5,9,12], target = 9
输出: 4
解释: 9 出现在 nums 中并且下标为 4=
示例 2:
输入: nums = [-1,0,3,5,9,12], target = 2
输出: -1
解释: 2 不存在 nums 中因此返回 -1
SOLUTION
在升序数组 nums 中寻找目标值 target,对于特定下标 i,比较 nums[i] 和 target 的大小:
- 如果 nums[i]=target,则下标 i 即为要寻找的下标;
- 如果 nums[i]>target,则 target 只可能在下标 i 的左侧;
- 如果 nums[i]<target,则 target 只可能在下标 i 的右侧。
基于上述事实,可以在有序数组中使用二分查找寻找目标值。
二分查找的做法是,定义查找的范围 [left,right],初始查找范围是整个数组。每次取查找范围的中点 mid,比较 nums[mid] 和 target 的大小,如果相等则 mid 即为要寻找的下标,如果不相等则根据 nums[mid] 和 target 的大小关系将查找范围缩小一半。
由于每次查找都会将查找范围缩小一半,因此二分查找的时间复杂度是 O(logn),其中 n 是数组的长度。
二分查找的条件是查找范围不为空,即 left≤right。如果 target 在数组中,二分查找可以保证找到 target,返回 target 在数组中的下标。如果 target 不在数组中,则当 left>right 时结束查找,返回 −1。
class Solution {
public int search(int[] nums, int target) {
int low = 0, high = nums.length - 1;
while (low <= high) {
int mid = (high - low) / 2 + low;
int num = nums[mid];
if (num == target) {
return mid;
} else if (num > target) {
high = mid - 1;
} else {
low = mid + 1;
}
}
return -1;
}
}
寻找两个正序数组中的中位数
给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。
算法的时间复杂度应该为 O(log (m+n)) 。
示例 1:
输入:nums1 = [1,3], nums2 = [2]
输出:2.00000
解释:合并数组 = [1,2,3] ,中位数 2
示例 2:
输入:nums1 = [1,2], nums2 = [3,4]
输出:2.50000
解释:合并数组 = [1,2,3,4] ,中位数 (2 + 3) / 2 = 2.5
示例 3:
输入:nums1 = [0,0], nums2 = [0,0]
输出:0.00000
示例 4:
输入:nums1 = [], nums2 = [1]
输出:1.00000
示例 5:
输入:nums1 = [2], nums2 = []
输出:2.00000
SOLUTION:二分查找
假设我们要找第 7 小的数字。
A: 1 3 4 9
B: 1 2 3 4 5 6 7 8 9
两个有序数组的长度分别是 4 和 9,长度之和是 13,中位数是两个有序数组中的第 7 个元素,因此需要找到第 k=7 个元素。
比较两个有序数组中下标为 k/2-1=2k/2−1=2 的数,即A[2] 和 B[2],如下面所示:
A: 1 3 4 9
↑
B: 1 2 3 4 5 6 7 8 9
↑
由于A[2]>B[2],因此排除B[0]到B[2],即数组B 的下标偏移(offset)变为 3,同时更新 k 的值:k=k-k/2=4。
下一步寻找,比较两个有序数组中下标为 k/2-1=1k/2−1=1 的数,即 A[1] 和B[4],如下面所示,其中方括号部分表示已经被排除的数。
A: 1 3 4 9
↑
B: [1 2 3] 4 5 6 7 8 9
↑
由于A[1]<B[4],因此排除A[0]到A[1],即数组A 的下标偏移变为2,同时更新 k 的值:k=k−k/2=2。
下一步寻找,比较两个有序数组中下标为 k/2-1=0的数,即比较A[2] 和B[3],如下面所示,其中方括号部分表示已经被排除的数。
A: [1 3] 4 9
↑
B: [1 2 3] 4 5 6 7 8 9
↑
由于A[2]=B[3],根据之前的规则,排除A 中的元素,因此排除A[2],即数组A 的下标偏移变为3,同时更新 k 的值:k=k−k/2=1。
由于 k 的值变成 11,因此比较两个有序数组中的未排除下标范围内的第一个数,其中较小的数即为第 kk 个数,由于A[3]>B[3],因此第 k 个数是B[3]=4
A: [1 3 4] 9
↑
B: [1 2 3] 4 5 6 7 8 9
↑
class Solution {
public double findMedianSortedArrays(int[] nums1, int[] nums2) {
int length1 = nums1.length, length2 = nums2.length;
int totalLength = length1 + length2;
if (totalLength % 2 == 1) {
int midIndex = totalLength / 2;
double median = getKthElement(nums1, nums2, midIndex + 1);
return median;
} else {
int midIndex1 = totalLength / 2 - 1, midIndex2 = totalLength / 2;
double median = (getKthElement(nums1, nums2, midIndex1 + 1) + getKthElement(nums1, nums2, midIndex2 + 1)) / 2.0;
return median;
}
}
public int getKthElement(int[] nums1, int[] nums2, int k) {
/* 主要思路:要找到第 k (k>1) 小的元素,那么就取 pivot1 = nums1[k/2-1] 和 pivot2 = nums2[k/2-1] 进行比较
* 这里的 "/" 表示整除
* nums1 中小于等于 pivot1 的元素有 nums1[0 .. k/2-2] 共计 k/2-1 个
* nums2 中小于等于 pivot2 的元素有 nums2[0 .. k/2-2] 共计 k/2-1 个
* 取 pivot = min(pivot1, pivot2),两个数组中小于等于 pivot 的元素共计不会超过 (k/2-1) + (k/2-1) <= k-2 个
* 这样 pivot 本身最大也只能是第 k-1 小的元素
* 如果 pivot = pivot1,那么 nums1[0 .. k/2-1] 都不可能是第 k 小的元素。把这些元素全部 "删除",剩下的作为新的 nums1 数组
* 如果 pivot = pivot2,那么 nums2[0 .. k/2-1] 都不可能是第 k 小的元素。把这些元素全部 "删除",剩下的作为新的 nums2 数组
* 由于我们 "删除" 了一些元素(这些元素都比第 k 小的元素要小),因此需要修改 k 的值,减去删除的数的个数
*/
int length1 = nums1.length, length2 = nums2.length;
int index1 = 0, index2 = 0;
int kthElement = 0;
while (true) {
// 边界情况
if (index1 == length1) {
return nums2[index2 + k - 1];
}
if (index2 == length2) {
return nums1[index1 + k - 1];
}
if (k == 1) {
return Math.min(nums1[index1], nums2[index2]);
}
// 正常情况
int half = k / 2;
int newIndex1 = Math.min(index1 + half, length1) - 1;
int newIndex2 = Math.min(index2 + half, length2) - 1;
int pivot1 = nums1[newIndex1], pivot2 = nums2[newIndex2];
if (pivot1 <= pivot2) {
k -= (newIndex1 - index1 + 1);
index1 = newIndex1 + 1;
} else {
k -= (newIndex2 - index2 + 1);
index2 = newIndex2 + 1;
}
}
}
}
在排序数组中查找元素的第一个和最后一个位置
给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
进阶:
- 你可以设计并实现时间复杂度为
O(log n)的算法解决此问题吗?
示例 1:
输入:nums = [5,7,7,8,8,10], target = 8
输出:[3,4]
示例 2:
输入:nums = [5,7,7,8,8,10], target = 6
输出:[-1,-1]
示例 3:
输入:nums = [], target = 0
输出:[-1,-1]
SOLUTION:二分查找
- 在进行二分查找时,low会增大,high会减小。
- 如果循环条件是low<=high,则循环结束时high在low前面。
- 要找右边的某个数时,要借助low实现,因为low会不断变大。
- 要找左边的某个数时,要借助high实现,因为high会不断变小。
- 要找=target的最左边的数时,也就是找满足>=target的最左边的数。
- 但是,当nums[mid]>=target时,无法判断nums[mid]是否是满足nums[mid]>=target的最左边的数。
- 所以不能让high = mid。
- 但是,当nums[mid]>=target时,可以判断nums[mid]是满足nums[mid]>=target的数。
- 所以,让high = mid - 1。这样,只要满足条件,high就变小,最终high会停在第一个不满足条件的点。
- 所以,当nums[mid]>=target时, high = mid - 1。
- 这样,最终high就会停在第一个不满足>=target的地方。
- 同理,要找=target的最右边的数时,也就是找<=target的最右边的数。
- 所以,当nums[mid]<=target时, low = mid + 1。
- 这样,最终low就会停在第一个不满足<=target的地方。
class Solution {
public int[] searchRange(int[] nums, int target) {
int left = getLeft(nums, target);
int right = getRight(nums, target);
if(right-left>1) return new int[] {left+1,right-1};
else return new int[] {-1,-1};
}
public int getLeft(int[] nums, int target){
int low = 0;
int high = nums.length - 1;
while (low <= high) {
int mid = low + (high - low) / 2;
if (nums[mid] > target) {
high = mid - 1;
} else if (nums[mid] < target) {
low = mid + 1;
} else {
high = mid - 1;
}
}
return high;
}
public int getRight(int[] nums, int target) {
int low = 0;
int high = nums.length - 1;
while (low <= high) {
int mid = low + (high - low) / 2;
if (nums[mid] > target) {
high = mid - 1;
} else if (nums[mid] < target) {
low = mid + 1;
} else {
low = mid + 1;
}
}
return low;
}
}
数组中的第K个最大元素
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
示例 1:
输入: [3,2,1,5,6,4] 和 k = 2
输出: 5
示例 2:
输入: [3,2,3,1,2,4,5,5,6] 和 k = 4
输出: 4
SOLUTION:快速排序
class Solution {
Random random = new Random();
public int findKthLargest(int[] nums, int k) {
return quickSelect(nums, 0, nums.length - 1, nums.length - k);
}
public int quickSelect(int[] a, int l, int r, int index) {
int q = randomPartition(a, l, r);
if (q == index) {
return a[q];
} else {
return q < index ? quickSelect(a, q + 1, r, index) : quickSelect(a, l, q - 1, index);
}
}
public int randomPartition(int[] a, int l, int r) {
int i = random.nextInt(r - l + 1) + l;
swap(a, i, r);
return partition(a, l, r);
}
public int partition(int[] a, int l, int r) {
int x = a[r], i = l - 1;
for (int j = l; j < r; ++j) {
if (a[j] <= x) {
swap(a, ++i, j);
}
}
swap(a, i + 1, r);
return i + 1;
}
public void swap(int[] a, int i, int j) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
动态规划
基本思想与策略
基本思想与分治法类似,也是将待求解的问题分解为若干个子问题(阶段),按顺序求解子阶段,前一子问题的解,为后一子问题的求解提供了有用的信息。在求解任一子问题时,列出各种可能的局部解,通过决策保留那些有可能达到最优的局部解,丢弃其他局部解。依次解决各子问题,最后一个子问题就是初始问题的解。
由于动态规划解决的问题多数有重叠子问题这个特点,为减少重复计算,对每一个子问题只解一次,将其不同阶段的不同状态保存在一个二维数组中。
与分治法最大的差别是:适合于用动态规划法求解的问题,经分解后得到的子问题往往不是互相独立的(即下一个子阶段的求解是建立在上一个子阶段的解的基础上,进行进一步的求解)。
使用情况
(1) 最优化原理:如果问题的最优解所包含的子问题的解也是最优的,就称该问题具有最优子结构,即满足最优化原理。
(2) 无后效性:即某阶段状态一旦确定,就不受这个状态以后决策的影响。也就是说,某状态以后的过程不会影响以前的状态,只与当前状态有关。
(3)有重叠子问题:即子问题之间是不独立的,一个子问题在下一阶段决策中可能被多次使用到。(该性质并不是动态规划适用的必要条件,但是如果没有这条性质,动态规划算法同其他算法相比就不具备优势)
基本步骤
动态规划所处理的问题是一个多阶段决策问题,一般由初始状态开始,通过对中间阶段决策的选择,达到结束状态。这些决策形成了一个决策序列,同时确定了完成整个过程的一条活动路线(通常是求最优的活动路线)。如图所示。动态规划的设计都有着一定的模式,一般要经历以下几个步骤。
初始状态→│决策1│→│决策2│→…→│决策n│→结束状态
图1 动态规划决策过程示意图
(1)划分阶段:按照问题的时间或空间特征,把问题分为若干个阶段。在划分阶段时,注意划分后的阶段一定要是有序的或者是可排序的,否则问题就无法求解。
(2)确定状态和状态变量:将问题发展到各个阶段时所处于的各种客观情况用不同的状态表示出来。当然,状态的选择要满足无后效性。
(3)确定决策并写出状态转移方程:因为决策和状态转移有着天然的联系,状态转移就是根据上一阶段的状态和决策来导出本阶段的状态。所以如果确定了决策,状态转移方程也就可写出。但事实上常常是反过来做,根据相邻两个阶段的状态之间的关系来确定决策方法和状态转移方程。
(4)寻找边界条件:给出的状态转移方程是一个递推式,需要一个递推的终止条件或边界条件。
一般,只要解决问题的阶段、状态和状态转移决策确定了,就可以写出状态转移方程(包括边界条件)。
实际应用中可以按以下几个简化的步骤进行设计:
(1)分析最优解的性质,并刻画其结构特征。
(2)递归的定义最优解。
(3)以自底向上或自顶向下的记忆化方式(备忘录法)计算出最优值
(4)根据计算最优值时得到的信息,构造问题的最优解
最长回文字符串
给你一个字符串 s,找到 s 中最长的回文子串。
示例 1:
输入:s = "babad"
输出:"bab"
解释:"aba" 同样是符合题意的答案。
示例 2:
输入:s = "cbbd"
输出:"bb"
示例 3:
输入:s = "a"
输出:"a"
示例 4:
输入:s = "ac"
输出:"a"
SOLUTION:动态规划
首先定义 P(i,j)。
P(i,j)= true, s[i,j]是回文串;
P(i,j)= false, s[i,j]不是回文串;
则P(i,j)=P(i+1,j−1)&&S[i]==S[j]
单个字符一定是回文串,因此把对角线先初始化为 true,即 P[i][i] = true。根据第 2 步的说明:当 P[i..j] 的长度为 2 时,只需要判断 s[i] 是否等于 s[j],所以二维表格对角线上的数值不会被参考。所以不设置 P[i][i] = true 也能得到正确结论。
public class Solution {
public String longestPalindrome(String s) {
// 特殊用例判断
int len = s.length();
if (len < 2) {
return s;
}
int maxLen = 1;
int begin = 0;
// dp[i][j] 表示 s[i, j] 是否是回文串
boolean[][] dp = new boolean[len][len];
char[] charArray = s.toCharArray();
for (int i = 0; i < len; i++) {
dp[i][i] = true;
}
for (int j = 1; j < len; j++) {
for (int i = 0; i < j; i++) {
if (charArray[i] != charArray[j]) {
dp[i][j] = false;
} else {
if (j - i < 3) {
dp[i][j] = true;
} else {
dp[i][j] = dp[i + 1][j - 1];
}
}
// 只要 dp[i][j] == true 成立,就表示子串 s[i..j] 是回文,此时记录回文长度和起始位置
if (dp[i][j] && j - i + 1 > maxLen) {
maxLen = j - i + 1;
begin = i;
}
}
}
return s.substring(begin, begin + maxLen);
}
}
接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
示例 1:

输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
输出:6
解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
示例 2:
输入:height = [4,2,0,3,2,5]
输出:9
SOLUTION:动态规划
对于下标 i,下雨后水能到达的最大高度等于下标 i 两边的最大高度的最小值,下标 i 处能接的雨水量等于下标 i 处的水能到达的最大高度减去 height[i]。
朴素的做法是对于数组 height 中的每个元素,分别向左和向右扫描并记录左边和右边的最大高度,然后计算每个下标位置能接的雨水量。假设数组 height 的长度为 n,该做法需要对每个下标位置使用 O(n) 的时间向两边扫描并得到最大高度,因此总时间复杂度是 O(n2)。
上述做法的时间复杂度较高是因为需要对每个下标位置都向两边扫描。如果已经知道每个位置两边的最大高度,则可以在 O(n) 的时间内得到能接的雨水总量。使用动态规划的方法,可以在 O(n) 的时间内预处理得到每个位置两边的最大高度。
创建两个长度为 n 的数组 leftMax 和 rightMax。对于 0≤i<n,leftMax[i] 表示下标 i 及其左边的位置中,height 的最大高度,rightMax[i] 表示下标 i 及其右边的位置中,height 的最大高度。
显然,leftMax[0]=height[0],rightMax[n−1]=height[n−1]。两个数组的其余元素的计算如下:
- 当 1≤i≤n−1 时,leftMax[i]=max(leftMax[i−1],height[i]);
- 当 0≤i≤n−2 时,rightMax[i]=max(rightMax[i+1],height[i])。
因此可以正向遍历数组 height 得到数组 leftMax 的每个元素值,反向遍历数组 height 得到数组 rightMax 的每个元素值。
在得到数组 leftMax 和 rightMax 的每个元素值之后,对于 0≤i<n,下标 i 处能接的雨水量等于 min(leftMax[i],rightMax[i])−height[i]。遍历每个下标位置即可得到能接的雨水总量。
动态规划做法可以由下图体现。
class Solution {
public int trap(int[] height) {
int n = height.length;
if (n == 0) {
return 0;
}
int[] leftMax = new int[n];
leftMax[0] = height[0];
for (int i = 1; i < n; ++i) {
leftMax[i] = Math.max(leftMax[i - 1], height[i]);
}
int[] rightMax = new int[n];
rightMax[n - 1] = height[n - 1];
for (int i = n - 2; i >= 0; --i) {
rightMax[i] = Math.max(rightMax[i + 1], height[i]);
}
int ans = 0;
for (int i = 0; i < n; ++i) {
ans += Math.min(leftMax[i], rightMax[i]) - height[i];
}
return ans;
}
}
爬楼梯
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
**注意:**给定 n 是一个正整数。
示例 1:
输入: 2
输出: 2
解释: 有两种方法可以爬到楼顶。
1. 1 阶 + 1 阶
2. 2 阶
示例 2:
输入: 3
输出: 3
解释: 有三种方法可以爬到楼顶。
1. 1 阶 + 1 阶 + 1 阶
2. 1 阶 + 2 阶
3. 2 阶 + 1 阶
SOLUTION:动态规划
本问题其实常规解法可以分成多个子问题,爬第n阶楼梯的方法数量,等于 2 部分之和
- 爬上 n−1 阶楼梯的方法数量。因为再爬1阶就能到第n阶
- 爬上 n−2 阶楼梯的方法数量,因为再爬2阶就能到第n阶
所以我们得到公式 dp[n]=dp[n−1]+dp[n−2]
同时需要初始化 dp[0]=1 和 dp[1]=1
时间复杂度:O(n)
class Solution {
public int climbStairs(int n) {
int[] dp = new int[n + 1];
dp[0] = 1;
dp[1] = 1;
for(int i = 2; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}
}
正则表达式匹配
给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 '.' 和 '*' 的正则表达式匹配。
'.'匹配任意单个字符'*'匹配零个或多个前面的那一个元素
所谓匹配,是要涵盖 整个 字符串 s的,而不是部分字符串。
示例 1:
输入:s = "aa" p = "a"
输出:false
解释:"a" 无法匹配 "aa" 整个字符串。
示例 2:
输入:s = "aa" p = "a*"
输出:true
解释:因为 '*' 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 'a'。因此,字符串 "aa" 可被视为 'a' 重复了一次。
示例 3:
输入:s = "ab" p = ".*"
输出:true
解释:".*" 表示可匹配零个或多个('*')任意字符('.')。
示例 4:
输入:s = "aab" p = "c*a*b"
输出:true
解释:因为 '*' 表示零个或多个,这里 'c' 为 0 个, 'a' 被重复一次。因此可以匹配字符串 "aab"。
示例 5:
输入:s = "mississippi" p = "mis*is*p*."
输出:false
SOLUTION:动态规划
dp[i][j] 表示 s 的前 i 个是否能被 p 的前 j 个匹配
-
如果
p.charAt(j) == s.charAt(i)则dp[i][j] = dp[i-1][j-1]; -
如果
p.charAt(j) == '.'则dp[i][j] = dp[i-1][j-1]; -
如果
p.charAt(j) == '*':- 如果
p.charAt(j-1) != s.charAt(i)则dp[i][j] = dp[i][j-2] - 如果
p.charAt(i-1) == s.charAt(i) or p.charAt(i-1) == '.':
dp[i][j] = dp[i-1][j] //in this case, a* counts as multiple aor dp[i][j] = dp[i][j-1] // in this case, a* counts as single aor dp[i][j] = dp[i][j-2] // in this case, a* counts as empty
- 如果
class Solution {
public boolean isMatch(String s, String p) {
int m = s.length();
int n = p.length();
boolean[][] f = new boolean[m + 1][n + 1];
f[0][0] = true;
for (int i = 0; i <= m; ++i) {
for (int j = 1; j <= n; ++j) {
if (p.charAt(j - 1) == '*') {
f[i][j] = f[i][j - 2];
if (matches(s, p, i, j - 1)) {
f[i][j] = f[i][j] || f[i - 1][j];
}
} else {
if (matches(s, p, i, j)) {
f[i][j] = f[i - 1][j - 1];
}
}
}
}
return f[m][n];
}
public boolean matches(String s, String p, int i, int j) {
if (i == 0) {
return false;
}
if (p.charAt(j - 1) == '.') {
return true;
}
return s.charAt(i - 1) == p.charAt(j - 1);
}
}
买卖股票的最佳时机
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
示例 1:
输入:[7,1,5,3,6,4]
输出:5
解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
示例 2:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这种情况下, 没有交易完成, 所以最大利润为 0。
SOLUTION:动态规划
class Solution {
public int maxProfit(int[] prices) {
int maxProfit = 0;
int minPrice = Integer.MAX_VALUE;
for(int i =0; i< prices.length; i++){
minPrice = Math.min(minPrice, prices[i]);
maxProfit = Math.max(maxProfit, prices[i] - minPrice);
}
return maxProfit;
}
}
二叉树的最大路径和
路径 被定义为一条从树中任意节点出发,沿父节点-子节点连接,达到任意节点的序列。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。
路径和 是路径中各节点值的总和。
给你一个二叉树的根节点 root ,返回其 最大路径和 。
示例 1:
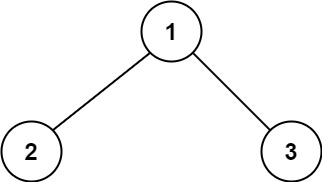
输入:root = [1,2,3]
输出:6
解释:最优路径是 2 -> 1 -> 3 ,路径和为 2 + 1 + 3 = 6
示例 2:
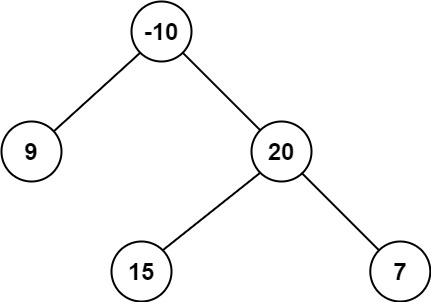
输入:root = [-10,9,20,null,null,15,7]
输出:42
解释:最优路径是 15 -> 20 -> 7 ,路径和为 15 + 20 + 7 = 42
SOLUTION: 动态规划
class Solution {
int maxSum = Integer.MIN_VALUE;
public int maxPathSum(TreeNode root) {
maxGain(root);
return maxSum;
}
public int maxGain(TreeNode node) {
if (node == null) {
return 0;
}
// 递归计算左右子节点的最大贡献值
// 只有在最大贡献值大于 0 时,才会选取对应子节点
int leftGain = Math.max(maxGain(node.left), 0);
int rightGain = Math.max(maxGain(node.right), 0);
// 节点的最大路径和取决于该节点的值与该节点的左右子节点的最大贡献值
int priceNewpath = node.val + leftGain + rightGain;
// 更新答案
maxSum = Math.max(maxSum, priceNewpath);
// 返回节点的最大贡献值
return node.val + Math.max(leftGain, rightGain);
}
}



评论区