




文章摘要(AI生成)
Apache ShardingSphere是一个由JDBC、Proxy和Sidecar组成的产品,支持独立部署和混合部署。ShardingSphere-JDBC是一个轻量级Java框架,提供额外服务,适用于任何基于JDBC的ORM框架。ShardingSphere-Proxy是一个数据库代理端,透明化提供服务,支持MySQL/PostgreSQL协议的客户端。ShardingSphere-Scaling是一个通用数据接入迁移和弹性伸缩解决方案。ShardingSphere-Sidecar是一个云原生数据库代理。ShardingSphere提供多种功能点,兼容多种数据库,支持熔断和限流等。数据分片提供标准分片算法、复合分片算法和Hint分片算法等。支持本地事务、XA事务和柔性事务,以及读写分离和高可用等特性。ShardingSphere-Scaling支持数据迁移和扩缩容,但不支持无主键表扩缩容。数据加密、影子库、可观察性等功能也得到支持。Sharding Proxy提供数据分片策略和分片操作支持。
Apache ShardingSphere 由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署 配合使用的产品组成。
| 组件 | 描述 | 应用 |
|---|---|---|
| ShardingSphere-JDBC | 轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。它使用客户端直连数据库,以 jar 包形式 提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。 | 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接 使用 JDBC;支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等;支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何 可使用 JDBC 访问的数据库 |
| ShardingSphere-Proxy | 定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持. | 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用;适用于任何兼容 MySQL/PostgreSQL 协议的的客户端。 |
| ShardingSphere-Scaling(实验室版本:4.1.0) | 是一个提供给用户的通用的 ShardingSphere 数据接入迁移,及弹性伸缩(随着业务规模的快速变化,也可能需要对现有的分片集群进行弹性扩容或缩容)的解决方案。 | |
| ShardingSphere-Sidecar(规划中) | 定位为 Kubernetes 的云原生数据库代理,以 Sidecar 的形式代理所有对数据库的访问。 |
sharding sphere推荐的应用混合架构

sharding sphere的功能
| 功能点 | 备注 |
|---|---|
| 数据库兼容 | 兼容多种数据库 |
| 管控 | 熔断:阻断 Apache ShardingSphere 和数据库的连接限流:面对超负荷的请求开启限流,以保护部分请求可以得以高质量的响应。 |
| 数据分片 | 标准分片算法:用于处理使用单一键作为分片键的 =、IN、BETWEEN AND、>、<、>=、<= 进行分片的场景。复合分片算法:用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。Hint 分片算法:用于处理使用 Hint 行(通过外部指定分片结果)分片的场景。 |
| 分布式事务 | 本地事务:完全支持非跨库事务和因逻辑异常导致的跨库事务,不支持网络其他异常导致的跨库事务XA 事务:支持数据分片后的跨库事务;两阶段提交保证操作的原子性和数据的强一致性;服务宕机重启后,提交/回滚中的事务可自动恢复; 支持同时使用 XA 和非 XA 的连接池柔性事务:支持数据分片后的跨库事务; 支持 RC 隔离级别;通过 undo 快照进行事务回滚;支持服务宕机后的,自动恢复提交中的事务 |
| 读写分离 | 提供一主多从的读写分离配置,可独立使用,也可配合数据分片使用;事务中的数据读写均用主库;基于 Hint 的强制主库路由。 |
| 高可用 | 不支持mysql多主模式 |
| 弹性伸缩 | ShardingSphere‐Scaling 是一个提供给用户的通用数据接入迁移及弹性伸缩的解决方案。支持:• 将外围数据迁移至 Apache ShardingSphere 所管理的数据库; • 将 Apache ShardingSphere 的数据节点进行扩容或缩容。不支持:• 无主键表扩缩容; • 复合主键表扩缩容; • 不支持在当前存储节点之上做迁移,需要准备一个全新的数据库集群作为迁移目标库。 |
| 数据加密 | 对数据库表中某个或多个列进行加解密;兼容所有常用 SQL。 |
| 影子库(全链路压测) | 用于全链路压测场景下,数据库层面的解决方案。可以将压测数据自动路由至用户指定的数据库 |
| 可观察性 | 支持APM、Tracing、Metrics |
Sharding Proxy
本地下载解压后部署:

配置数据源:
schemaName: test
dataSources:
cashcow_birch:
url: jdbc:mysql://
username:
password:
connectionTimeoutMilliseconds: 3000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHARDING
tables:
recv_sub_account_order:
actualDataNodes: test.order_${0..36}
tableStrategy:
standard:
shardingColumn: order_uid
shardingAlgorithmName: recv_order_inline
keyGenerateStrategy:
column: recv_order_uid
keyGeneratorName: snowflake
bindingTables:
- recv_sub_account_order
defaultTableStrategy:
none:
shardingAlgorithms:
recv_order_inline:
type: INLINE
props:
algorithm-expression: order_${order_uid % 37}
keyGenerators:
snowflake:
type: SNOWFLAKE
props:
worker-id: 123
配置端口后,启动client(启动命令sh sharding-sphere-test/bin/start.sh 3308),使用navicat访问服务端口3308,即可连接到代理库:
代理库视图如下:
原库视图为:
在代理库可以正常执行插入、查询sql语句,不用计算路由:
插入、查询示例:

Sharding JDBC
数据分片
| 分片策略 | 分片键类型 | 分片算法 | sql分片操作支持 |
|---|---|---|---|
| 标准分片 | 单分片键 | 精确分片算法:用于处理使用单一键作为分片键的=与IN进行分片的场景。范围分片算法:用于处理使用单一键作为分片键的BETWEEN AND进行分片的场景。 | |
| 复合分片 | 多分片键 | 复合分片算法:处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。 | =, IN和BETWEEN AND |
| Hint分片 | 非当前表字段 | Hint分片算法:用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用 | =, IN和BETWEEN AND |
| 行表达式分片 | 单分片键 | 使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: t_user_$->{u_id % 8} 表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7。 |
=和IN |
使用中遇到的问题
| 问题 | 描述 | 备注 |
|---|---|---|
| 服务启动时强制扫描表结构 | 一位同学执行分表字段变更语句时,其他通讯与该字段无关的代码上线在启动时会报错,导致服务启动失败 | 升级shardingsphere |
| 未分表与分表不是同一个数据源,导致写分表的事务未生效 | 不分表的库表也通过shardingsphere统一数据源代理 | |
| 历史数据迁移使用单独服务 | 最好使用单独的代码进行部署,不要代码混布 |
原理:你提交的sql是如何执行的?
解析
将sql进行解析成抽象语法树
路由
携带分片键的sql使用分片路由,不携带分片键的sql使用广播路由
使用分片键做关联查询时,应配置绑定表关系,避免产生笛卡尔积路由。
笛卡尔积路由:
-- 给定订单表t_order 与订单明细表t_order_item,均使用order_id做分片建
SELECT * FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
-- 路由后的sql
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
设置绑定表: spring.shardingsphere.sharding.binding-tables[0] = t_order,t_order_item
改写
将路由后的sql进行改写:
1.sql中含有表名之外可能含有表名称的类似字符
2.如果SQL中定义了表的别名,则无需连同别名一起修改,即使别名与表名相同亦是如此
3.以下3种情况需要补列:
1)使用GROUP BY和ORDER BY时,查询结果未包含分组和排序条件导致结果无法归并`
SELECT order_id FROM t_order ORDER BY user_id;
-- 补列后
SELECT order_id, user_id AS ORDER_BY_DERIVED_0 FROM t_order ORDER BY user_id;
2)使用AVG聚合函数,在分布式的场景中,使用avg1 + avg2 + avg3 / 3计算平均值并不正确,需要改写为 (sum1 + sum2 + sum3) / (count1 + count2 + count3)
例如对三数组(1,2)(3,4)(5,6,7)求平均值,(1.5+3.5+6)/3=3.67, (3+7+18)/7=4;两者并不相等。
- 在执行INSERT的SQL语句时,会自动添加为插入行的分布式主键赋值
4.分页修正:将limit m,n 变为limit 0,(m+n)
5.批量修正:对批量插入语句拆分到分表中
执行
将路由后的sql按数据源分组,获取最优的数据库连接,然后分组执行
归并
- 排序归并:对多个有序的数组进行排序,归并排序是最适合此场景的排序算法。使用流式归并的方式,每次仅每个分组获取唯一正确的一条数据,极大的节省了内存的消耗。
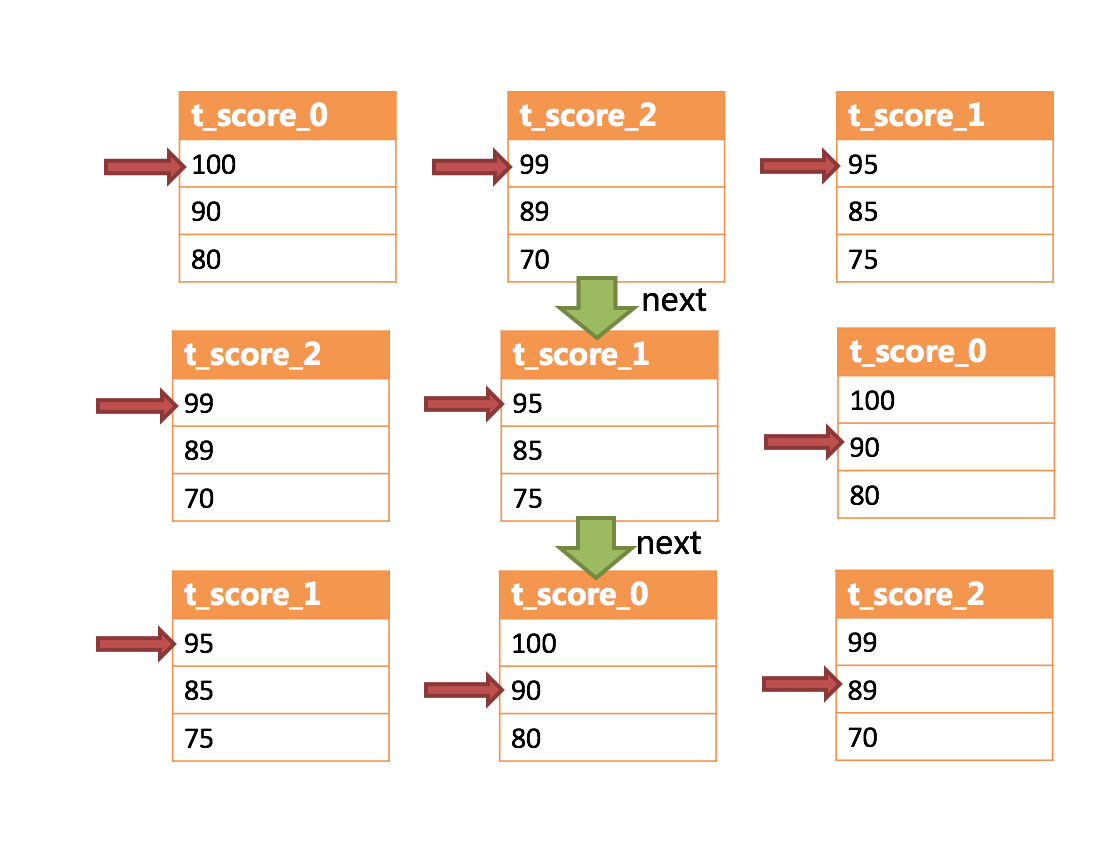
- 分组归并:SQL的排序项与分组项的字段以及排序类型(ASC或DESC)一致时采用流式归并;不一致时则采用内存分组归并

- 聚合归并:
MAX和MIN:对每一个同组的结果集数据进行比较,SUM和COUNT:将每一个同组的结果集数据进行累加
- 分页归并:
- 不会将所有结果加载到内存中,但是如果涉及排序仍会占用sharding sphere大量的内存,最好不要使用limit
- 可以保证ID的连续性,通过ID进行分页是比较好的解决方案




评论区