




文章摘要(AI生成)
RocketMQ是一种消息中间件,与ActiveMQ、RabbitMQ和Kafka相比,它使用Java、Erlang、JavaScript和Scala等开发语言,具有万级到十万级的单机吞吐量。RocketMQ的一大优势是可以支持大量的Topic,即使在同等数量的机器下也能支持大量的Topic。然而,当Topic数量从几十个增加到几百个时,吞吐量会显著下降。Kafka是另一种消息中间件,具有高毫秒级的时效性、高可用性和可靠性,适用于大规模Topic和复杂业务场景。它是分布式的,可以保证消息不会丢失。RocketMQ和Kafka都有各自的优势和劣势,例如RocketMQ功能较为完备,而Kafka在分布式扩展性和可靠性方面表现较好。总体而言,RocketMQ和Kafka都在大数据领域有广泛应用,具有不同的特点和适用场景。
RocketMQ介绍
不同消息中间件性能对比
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 开发语⾔ | java | erlang | java | scala |
| 单机吞吐量 | 万级 | 万级 | ⼗万级 | ⼗万级 |
| Topic数量对吞吐量的影响 | – | – | Topic可以达到⼏百、⼏千个的级别,吞吐量会有⼩幅度的下降。这是RocketMQ的⼀⼤优势,可在同等数量机器下⽀撑⼤量的Topic | Topic从⼏⼗个到⼏百个的时候,吞吐量会⼤幅下降。所以在同等机器数量下,Kafka尽量保证Topic数量不要过多。如果⽀撑⼤规模Topic需要增加更多的机器 |
| 时效性 | 毫秒级 | 微秒级 | 毫秒级 | 毫秒级 |
| 可⽤性 | 高,主从架构 | 高,主从架构 | 非常高,分布式架构 | ⾮常⾼,Kafka是分布式的,⼀个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可⽤ |
| 消息可靠性 | 有较低的概率丢失数据 | – | 经过参数优化配置,可以做到零丢失 | 经过参数配置,可以做到零丢失 |
| 功能⽀持 | MQ领域的功能及其完备 | 基于erlang开发,所以并发性能极强,性能极好,延时低 | MQ功能较为完备,分布式扩展性好 | 功能较为简单,主要⽀持主要的MQ功能,像⼀些消息查询,消息回溯等功能没有提供,毕竟是为⼤数据准备的,在⼤数据领域应⽤⼴ |
| 优势 | ⾮常成熟,功能强⼤,在业内⼤量公司和项⽬中都有应⽤ | erlang语⾔开发,性能极好、延时很低,吞吐量万级、MQ功能完备,管理界⾯⾮常好,社区活跃;互联⽹公司使⽤较多 | 接⼝简单易⽤,阿⾥出品有保障,吞吐量⼤,分布式扩展⽅便、社区⽐较活跃,⽀持⼤规模的Topic、⽀持复杂的业务场景,可以基于源码进⾏定制开发 | 超⾼吞吐量,ms级的时延,极⾼的可⽤性和可靠性,分布式扩展⽅便 |
| 劣势 | 偶尔有较低概率丢失消息,社区活跃度不⾼ | 吞吐量较低,erlang语⾳开发不容易进⾏定制开发,集群动态扩展麻烦 | 接⼝不是按照标准JMS规范⾛的,有的系统迁移要修改⼤量的代码,技术有被抛弃的⻛险 | 有可能进⾏消息的重复消费 |
| 应⽤ | 主要⽤于解耦和异步,较少⽤在⼤规模吞吐的场景中 | 都有使⽤ | ⽤于⼤规模吞吐、复杂业务中 | 在⼤数据的实时计算和⽇志采集中被⼤规模使⽤,是业界的标准 |
| 客户端语⾔ | – | java、c++、python | java | java、c++、go、python |
功能对比
| 对⽐项 | Kafka | RocketMQ | RabbitMQ |
|---|---|---|---|
| 顺序消息 | ⽀持 | ⽀持 | ⽀持 |
| 延时消息 | 不⽀持 | 只⽀持特定Level | 不⽀持 |
| 事务消息 | 不⽀持 | ⽀持 | 不⽀持 |
| 消息过滤 | ⽀持 | ⽀持 | 不⽀持 |
| 消息查询 | 不⽀持 | ⽀持 | 不⽀持 |
| 消费失败重试 | 不⽀持 | ⽀持 | ⽀持 |
| 批量发送 | ⽀持 | ⽀持 | 不⽀持 |
服务发现-NameServer
RocketMQ集群中的各个服务都需要通过NameServer来了解集群中各个服务的状态。
nameserver的稳定性⾮常⾼。原因有⼆:
- nameserver互相独⽴,彼此没有通信关系,单台nameserver挂掉,不影响其他
- nameserver不会有频繁的读写,所以性能开销⾮常⼩,稳定性很⾼。
NameServer工作机制
NameServer作为⼀个名称服务,需要提供服务注册、服务剔除、服务发现这些基本功能,但是NameServer节点之间并不通信,在某个时刻各个节点数据可能不⼀致的情况下,如何保证客户端可以最终拿到正确的数据。下⾯分别从路由注册、路由剔除,路由发现三个⻆度进⾏介绍。
路由注册
NameServer节点之间是互不通信的,⽆法进⾏数据复制。RocketMQ采取的策略是,在Broker节点在启动的时候,轮训NameServer列表,与每个NameServer节点建⽴⻓连接,发起注册请求。NameServer内部会维护⼀个Broker表,⽤来动态存储Broker的信息。同时,Broker节点为了证明⾃⼰是存活的,会将最新的信息上报给NameServer,然后每隔30秒向NameServer发送⼼跳包,⼼跳包中包含BrokerId、Broker地址、Broker名称、Broker所属集群名称、队列和brokerIP对应关系等等,然后NameServer接收到⼼跳包后,会更新时间戳,记录这个Broker的最新存活时间。NameServer在处理⼼跳包的时候,存在多个Broker同时操作⼀张Broker表,为了防⽌并发修改Broker表导致不安全,路由注册操作引⼊了ReadWriteLock读写锁,这个设计亮点允许多个消息⽣产者并发读,保证了消息发送时的⾼并发,但是同⼀时刻NameServer只能处理⼀个Broker⼼跳包,多个⼼跳包串⾏处理。这也是读写锁的经典使⽤场景,即读多写少。
路由剔除
正常情况下,如果Broker关闭,则会与NameServer断开⻓连接,Netty的通道关闭监听器会监听到连接断开事件,然后会将这个Broker信息剔除掉。
异常情况下,NameServer中有⼀个定时任务,每隔10秒扫描⼀下Broker表,如果某个Broker的⼼跳包最新时间戳距离当前时间超多120秒,也会判定Broker失效并将其移除。特别的,对于⼀些⽇常运维⼯作,例如:Broker升级,RocketMQ提供了⼀种优雅剔除路由信息的⽅式。如在升级⼀个Master节点之前,可以先通过命令⾏⼯具禁⽌这个Broker的写权限,发送消息到这个Broker的请求,都会收到⼀个NO_PERMISSION响应,客户端会⾃动重试其他的Broker。
当观察到这个broker没有流量后,再将这个broker移除。
路由发现
路由发现是客户端的⾏为,这⾥的客户端主要说的是⽣产者和消费者。具体来说:
对于⽣产者,可以发送消息到多个Topic,因此⼀般是在发送第⼀条消息时,才会根据Topic获取从NameServer获取路由信息。
对于消费者,订阅的Topic⼀般是固定的,所在在启动时就会拉取。
那么⽣产者/消费者在⼯作的过程中,如果路由信息发⽣了变化怎么处理呢?如:Broker集群新增了节点,节点宕机或者Queue的数量发⽣了变化。前⾯讲解NameServer在路由注册或者路由剔除过程中,并不会主动推送会客户端的,这意味着,需要由客户端拉取主题的最新路由信息。事实上,RocketMQ客户端提供了定时拉取Topic最新路由信息的机制:通过定时线程池,根据指定的拉取时间间隔,周期性的从NameServer并获取最新的路由表,在拉取时,会把当前启动的Producer和Consumer需要使⽤到的Topic列表放到⼀个集合中,逐个从NameServer进⾏更新。
客户端NameServer选择策略
具体选择哪个NameServer,也是使⽤round-robin的策略。需要注意的是,尽管使⽤round-robin策略,但是在选择了⼀个NameServer节点之后,后⾯总是会优先选择这个NameServer,除⾮与这个NameServer节点通信出现异常的情况下,才会选择其他节点。
通常NameServer节点是固定的⼏个,但是客户端的数量可能是成百上千,为了减少每个NameServer节点的压⼒,所以每个客户端节点只随机与其中⼀个NameServer节点建⽴连接。
消息存储-Broker
Broker是RocketMQ的核⼼,消息存储是broker的核⼼,提供了消息的接收,存储,拉取等功能,⼀般都需要保证Broker的⾼可⽤,所以会配置BrokerSlave,当Master挂掉之后,Consumer仍然可以消费Slave
Broker作用有两个:
1、将生产者发送得消息存储到MappedFile中,当前MappedFile写满会创建一个新的文件。为此维护了一个MappedFileQueue来存储收到的消息
2、从MappedFileQueue读取消息,但是为了方便快速读取,需要通过一个ConsumeQueue来快速定位到要查找消息所在的MappedFile文件。
消费者发送消息,broker内存存储的流转图如下:
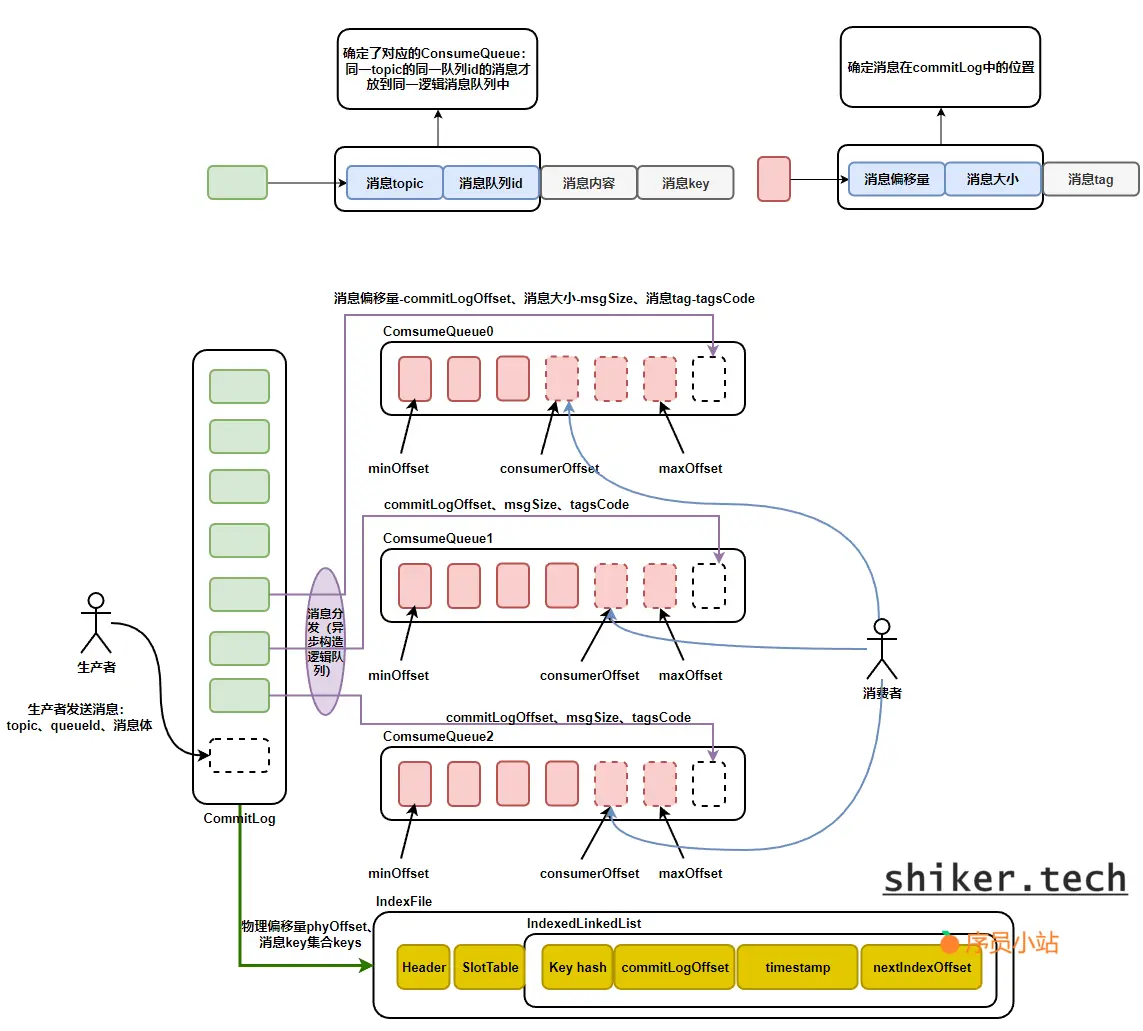
消息内容存储-CommitLog
⼀台Broker服务器只有⼀个CommitLog⽂件(组),RocketMQ会将所有主题的消息存储在同⼀个⽂件中,这个⽂件中就存储着⼀条条Message,每条Message都会按照顺序写⼊。
与其他中间件一样,CommitLog也支持不同得落盘策略:同步刷盘、异步刷盘但开启系统缓冲区、异步刷盘但关闭系统缓冲区
消息内容读取-ConsumeQueue
为了加速ConsumeQueue消息条⽬的检索速度和节省磁盘空间,每⼀个ConsumeQueue条⽬不会存储消息的全量信息,而是记录了CommitLog在磁盘中的偏移量,大小和消息tag。当读取消息时,CommitLog会调用ConsumeQueue中的方法计算出当前消息所在的MappedFile中的位置,从而返回对应的消息内容。
消息索引构建-Index
RocketMQ引⼊Hash索引机制,为消息建⽴索引,它的键就是MessageKey和UniqueKey。HashMap的设计包括两个基本点:Hash槽与Hash冲突的链表结构。IndexFile总共包含IndexHeader、Hash槽、Hash条⽬(数据)。
在Broker端,可以通过UniqueKey来计算Hash槽的位置,从⽽找到Index索引数据。从Index索引中拿到消息的物理偏移量,最后根据消息物理偏移量,直接到CommitLog⽂件中去找就可以了。这样构建完Index索引之后,根据MessageKey或UniqueKey查询消息就简单了。⽐如通过RocketMQ客户端⼯具,根据UniqueKey来查询消息。
文件清除
RocketMQ顺序写Commitlog、ConsumeQueue⽂件,所有写操作全部落在最后⼀个CommitLog或ConsumeQueue⽂件上,之前的⽂件在下⼀个⽂件创建后,将不会再被更新。
RocketMQ清除过期⽂件的⽅法是:如果⾮当前写⽂件在⼀定时间间隔内没有再次被更新,则认为是过期⽂件,可以被删除,RocketMQ不会管这个这个⽂件上的消息是否被全部消费。默认每个⽂件的过期时间为72⼩时。通过在Broker配置⽂件中设置fileReservedTime来改变过期时间,单位为⼩时。
消息生产者-Producer
RocketMQ发送消息分为三种实现⽅式:同步发送、异步发送、单向发送。⽬前的MQ中间件从存储模型来看,分为需要持久化和不需要持久化两种。
消息格式
发送的消息中包含以下属性:
- tags:消息TAG,⽤于消息过滤
- keys:消息索引键
- waitStoreMsgOK:消息发送时是否等消息存储完成后再返回
- DELAY:消息延迟级别,⽤于定时消息或消息重试
消息发送的主要流程
消息发送流程主要是:验证消息、查找路由、消息发送(包含异常处理机制)。
消息验证:主要是进⾏消息的⻓度验证。
查找路由:⼀个topic有多个队列,分散在不同的broker。producer在发送消息的时候,需要选择⼀个队列。消息发送之前,⾸先需要获取topic的路由信息,如果是第⼀次,则会从namesrv获取topic元数据,获取后会缓存下来,以后从缓存中获取。
消息发送:单条消息发送时,消息体的内容将保存在body中;批量消息发送,需要将多条消息的内容存储在body中,RocketMQ 对多条消息内容进⾏固定格式进⾏存储。
消息消费者-Comsumer
Push模式下的Consumer启动:
public synchronized void start() throws MQClientException {
switch (this.serviceState) {
case CREATE_JUST:
log.info("the consumer [{}] start beginning. messageModel={}, isUnitMode={}", this.defaultMQPushConsumer.getConsumerGroup(),
this.defaultMQPushConsumer.getMessageModel(), this.defaultMQPushConsumer.isUnitMode());
this.serviceState = ServiceState.START_FAILED;
/**
* 1、基本的参数检查,group name不能是DEFAULT_CONSUMER,检查配置信息,
* 主要检查消费者组(consumeGroup)、消息消费方式(messageModel)、
* 消息消费开始偏移量(consumeFromWhere)、消息队列分配算法(AllocateMessageQueueStrategy)、
* 订阅消息主题(Map<topic,sub expression ),消息回调监听器(MessageListener)、
* 顺序消息模式时是否只有一个消息队列等等。
*/
this.checkConfig();
/**
* 2、将DefaultMQPushConsumer的订阅信息copy到RebalanceService中
* 如果是cluster模式,如果订阅了topic,则自动订阅topic
*/
this.copySubscription();
/**
* 3、修改InstanceName参数值为PID
*/
if (this.defaultMQPushConsumer.getMessageModel() == MessageModel.CLUSTERING) {
this.defaultMQPushConsumer.changeInstanceNameToPID();
}
/**
* 4、新建一个MQClientInstance,客户端管理类,所有的i/o类操作由它管理
* 缓存客户端和topic信息,各种service
* 一个进程只有一个实例,这个实例在一个JVM中消费者和生产者共用,
* MQClientManager中维护了一个factoryTable,类型为ConcurrentMap,
* 保存了clintId和MQClientInstance
*/
this.mQClientFactory = MQClientManager.getInstance().getOrCreateMQClientInstance(this.defaultMQPushConsumer, this.rpcHook);
/**
* 5、Queue分配策略,默认AVG
*/
this.rebalanceImpl.setConsumerGroup(this.defaultMQPushConsumer.getConsumerGroup());
this.rebalanceImpl.setMessageModel(this.defaultMQPushConsumer.getMessageModel());
/**
* 6、队列默认分配算法
*/
this.rebalanceImpl.setAllocateMessageQueueStrategy(this.defaultMQPushConsumer.getAllocateMessageQueueStrategy());
//pullAPIWrapper拉取消息的API包装类,主要有消息的拉取方法和接受拉取到的消息
this.rebalanceImpl.setmQClientFactory(this.mQClientFactory);
this.pullAPIWrapper = new PullAPIWrapper(
mQClientFactory,
this.defaultMQPushConsumer.getConsumerGroup(), isUnitMode());
/**
* 7、消息被客户端过滤时会回调hook
*/
this.pullAPIWrapper.registerFilterMessageHook(filterMessageHookList);
/**
* 8、消费进度存储,如果是集群模式,使用远程存储RemoteBrokerOffsetStore,
* 如果是广播模式,则使用本地存储LocalFileOffsetStore,
*/
if (this.defaultMQPushConsumer.getOffsetStore() != null) {
this.offsetStore = this.defaultMQPushConsumer.getOffsetStore();
} else {
switch (this.defaultMQPushConsumer.getMessageModel()) {
case BROADCASTING:
this.offsetStore = new LocalFileOffsetStore(this.mQClientFactory, this.defaultMQPushConsumer.getConsumerGroup());
break;
case CLUSTERING:
this.offsetStore = new RemoteBrokerOffsetStore(this.mQClientFactory, this.defaultMQPushConsumer.getConsumerGroup());
break;
default:
break;
}
this.defaultMQPushConsumer.setOffsetStore(this.offsetStore);
}
/**
* 9、加载消息进度
*
* offsetStore是用来操作消费进度的对象,我们看一下RemoteBrokerOffsetStore对象,
* push模式消费进度最后持久化在broker端,但是consumer端在内存中也持有消费进度,
* RemoteBrokerOffsetStore参数
*/
this.offsetStore.load();
/**
* 10、判断是顺序消息还是并发消息,消费服务,顺序和并发消息逻辑不同,
* 接收消息并调用listener消费,处理消费结果
*/
if (this.getMessageListenerInner() instanceof MessageListenerOrderly) {
this.consumeOrderly = true;
this.consumeMessageService =
new ConsumeMessageOrderlyService(this, (MessageListenerOrderly) this.getMessageListenerInner());
} else if (this.getMessageListenerInner() instanceof MessageListenerConcurrently) {
this.consumeOrderly = false;
this.consumeMessageService =
new ConsumeMessageConcurrentlyService(this, (MessageListenerConcurrently) this.getMessageListenerInner());
}
/**
* 11、消息消费服务并启动
*/
this.consumeMessageService.start();
/**
* 12、注册消费者
*/
boolean registerOK = mQClientFactory.registerConsumer(this.defaultMQPushConsumer.getConsumerGroup(), this);
if (!registerOK) {
this.serviceState = ServiceState.CREATE_JUST;
this.consumeMessageService.shutdown(defaultMQPushConsumer.getAwaitTerminationMillisWhenShutdown());
throw new MQClientException("The consumer group[" + this.defaultMQPushConsumer.getConsumerGroup()
+ "] has been created before, specify another name please." + FAQUrl.suggestTodo(FAQUrl.GROUP_NAME_DUPLICATE_URL),
null);
}
/**
* 13、启动MQClientInstance,会启动PullMessageService和RebalanceService
*/
mQClientFactory.start();
log.info("the consumer [{}] start OK.", this.defaultMQPushConsumer.getConsumerGroup());
this.serviceState = ServiceState.RUNNING;
break;
case RUNNING:
case START_FAILED:
case SHUTDOWN_ALREADY:
throw new MQClientException("The PushConsumer service state not OK, maybe started once, "
+ this.serviceState
+ FAQUrl.suggestTodo(FAQUrl.CLIENT_SERVICE_NOT_OK),
null);
default:
break;
}
/**
* 14、从NameServer更新topic路由和订阅信息
*/
this.updateTopicSubscribeInfoWhenSubscriptionChanged();
/**
* 检测broker状态
*/
this.mQClientFactory.checkClientInBroker();
/**
* 15、发送心跳,同步consumer配置到broker,同步FilterClass到FilterServer(PushConsumer)
*/
this.mQClientFactory.sendHeartbeatToAllBrokerWithLock();
/**
* 16、做一次re-balance
*/
this.mQClientFactory.rebalanceImmediately();
}
Pull模式下Comusmer启动:
public synchronized void start() throws MQClientException {
switch (this.serviceState) {
case CREATE_JUST:
this.serviceState = ServiceState.START_FAILED;
/**
* 1、基本的参数检查,group name不能是DEFAULT_CONSUMER,检查配置信息,
* 主要检查消费者组(consumeGroup)、消息消费方式(messageModel)、
* 消息消费开始偏移量(consumeFromWhere)、消息队列分配算法(AllocateMessageQueueStrategy)、
* 订阅消息主题(Map<topic,sub expression ),消息回调监听器(MessageListener)、
* 顺序消息模式时是否只有一个消息队列等等。
*/
this.checkConfig();
/**
* 2、将DefaultMQPushConsumer的订阅信息copy到RebalanceService中
* 如果是cluster模式,如果订阅了topic,则自动订阅topic
*/
this.copySubscription();
/**
* 3、修改InstanceName参数值为PID
*/
if (this.defaultMQPullConsumer.getMessageModel() == MessageModel.CLUSTERING) {
this.defaultMQPullConsumer.changeInstanceNameToPID();
}
/**
* 4、新建一个MQClientInstance,客户端管理类,所有的i/o类操作由它管理
* 缓存客户端和topic信息,各种service
* 一个进程只有一个实例,这个实例在一个JVM中消费者和生产者共用,
* MQClientManager中维护了一个factoryTable,类型为ConcurrentMap,
* 保存了clintId和MQClientInstance
*/
this.mQClientFactory = MQClientManager.getInstance().getOrCreateMQClientInstance(this.defaultMQPullConsumer, this.rpcHook);
/**
* 5、Queue分配策略,默认AVG
*/
this.rebalanceImpl.setConsumerGroup(this.defaultMQPullConsumer.getConsumerGroup());
this.rebalanceImpl.setMessageModel(this.defaultMQPullConsumer.getMessageModel());
/**
* 6、队列默认分配算法
*/ this.rebalanceImpl.setAllocateMessageQueueStrategy(this.defaultMQPullConsumer.getAllocateMessageQueueStrategy());
this.rebalanceImpl.setmQClientFactory(this.mQClientFactory);
this.pullAPIWrapper = new PullAPIWrapper(
mQClientFactory,
this.defaultMQPullConsumer.getConsumerGroup(), isUnitMode());
/**
* 7、消息被客户端过滤时会回调hook
*/
this.pullAPIWrapper.registerFilterMessageHook(filterMessageHookList);
/**
* 8、消费进度存储,如果是集群模式,使用远程存储RemoteBrokerOffsetStore,
* 如果是广播模式,则使用本地存储LocalFileOffsetStore,
*/
if (this.defaultMQPullConsumer.getOffsetStore() != null) {
this.offsetStore = this.defaultMQPullConsumer.getOffsetStore();
} else {
switch (this.defaultMQPullConsumer.getMessageModel()) {
case BROADCASTING://⼴播消息本地持久化offset
this.offsetStore = new LocalFileOffsetStore(this.mQClientFactory, this.defaultMQPullConsumer.getConsumerGroup());
break;
case CLUSTERING: //集群模式持久化到broker
this.offsetStore = new RemoteBrokerOffsetStore(this.mQClientFactory, this.defaultMQPullConsumer.getConsumerGroup());
break;
default:
break;
}
this.defaultMQPullConsumer.setOffsetStore(this.offsetStore);
}
/**
* 9、加载消息进度
*
* offsetStore是用来操作消费进度的对象,我们看一下RemoteBrokerOffsetStore对象,
* push模式消费进度最后持久化在broker端,但是consumer端在内存中也持有消费进度,
* RemoteBrokerOffsetStore参数
*/
this.offsetStore.load();
/**
* 10、注册消费者
*/
boolean registerOK = mQClientFactory.registerConsumer(this.defaultMQPullConsumer.getConsumerGroup(), this);
if (!registerOK) {
this.serviceState = ServiceState.CREATE_JUST;
throw new MQClientException("The consumer group[" + this.defaultMQPullConsumer.getConsumerGroup()
+ "] has been created before, specify another name please." + FAQUrl.suggestTodo(FAQUrl.GROUP_NAME_DUPLICATE_URL),
null);
}
/**
* 13、启动MQClientInstance,会启动PullMessageService和RebalanceService
*/
mQClientFactory.start();
log.info("the consumer [{}] start OK", this.defaultMQPullConsumer.getConsumerGroup());
this.serviceState = ServiceState.RUNNING;
break;
case RUNNING:
case START_FAILED:
case SHUTDOWN_ALREADY:
throw new MQClientException("The PullConsumer service state not OK, maybe started once, "
+ this.serviceState
+ FAQUrl.suggestTodo(FAQUrl.CLIENT_SERVICE_NOT_OK),
null);
default:
break;
}
}
相对于Pull模式,Push提交过程多了消费服务的配置和启动流程,并且需要在消费端维护topic和broker的状态。
而对于Pull模式,我们可以通过⻓轮询机制来减少频繁的客户端连接对服务端性能的消耗,长轮询,顾名思义,它不同于常规轮询⽅式。常规的轮询⽅式为客户端发起请求,服务端接收后该请求后⽴即进⾏相应的⽅式。 ⻓轮询本质上仍旧是轮询,它与轮询不同之处在于,当服务端接收到客户端的请求后,服务端不会⽴即将数据返回给客户端,⽽是会先将这个请求hold住,判断服务器端数据是否有更新。如果有更新,则对客户端进⾏响应,如果⼀直没有数据,则它会在⻓轮询超时时间之前⼀直hold住请求并检测是否有数据更新,直到有数据或者超时后才返回。



评论区