




文章摘要(AI生成)
Elasticsearch是一个分布式、可扩展、近实时的搜索与数据分析引擎,底层使用了Lucene。ES集群由数据节点和主节点构成,数据节点负责存储数据,主节点负责管理集群。ES支持分片和副本,倒排索引提高了搜索速度。ES客户端包括Jest client、Rest client、Transport client、Node client,各有优缺点。Spring Boot集成ES需要根据版本匹配,spring data elastic search提供了方便的查询模块。总的来说,ES是一种强大的全文搜索引擎,适用于处理大规模数据的搜索和分析工作。
基础知识
ELASTIC SEARCH
Lucene:全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,以及部分文本分析引擎。
SOLR与elastic search的底层都借用了Lucene来实现的。而elastic search是一个分布式、可扩展、近实时的搜索与数据分析引擎。
集群:ES集群由一个或多个Elasticsearch节点组成,每个节点配置相同的 cluster.name 即可加入集群,默认值为 “elasticsearch”。确保不同的环境中使用不同的集群名称,否则最终会导致节点加入错误的集群。一个集群有数据节点和主节点构成:
数据节点负责数据的存储和相关的操作,例如对数据进行增、删、改、查和聚合等操作,所以数据节点(data节点)对机器配置要求比较高,对CPU、内存和I/O的消耗很大。通常随着集群的扩大,需要增加更多的数据节点来提高性能和可用性。
候选主节点可以被选举为主节点(master节点),集群中只有候选主节点才有选举权和被选举权,其他节点不参与选举的工作。主节点负责创建索引、删除索引、跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点、追踪集群中节点的状态等,稳定的主节点对集群的健康是非常重要的
**分片:**ES支持PB级全文搜索,当索引上的数据量太大的时候,ES通过水平拆分的方式将一个索引上的数据拆分出来分配到不同的数据块上,拆分出来的数据库块称之为一个分片。
**副本:**就是对分片的Copy,每个主分片都有一个或多个副本分片,当主分片异常时,副本可以提供数据的查询等操作。主分片和对应的副本分片是不会在同一个节点上的,所以副本分片数的最大值是 n -1(其中n为节点数)。
ES存储和查询的原理
Index(索引):相当于mysql的库
Mapping映射:相当于mysql 的表结构
Document(文档):相当于mysql的表中的一条数据, docId 文档的唯一标识
查询原理如下:
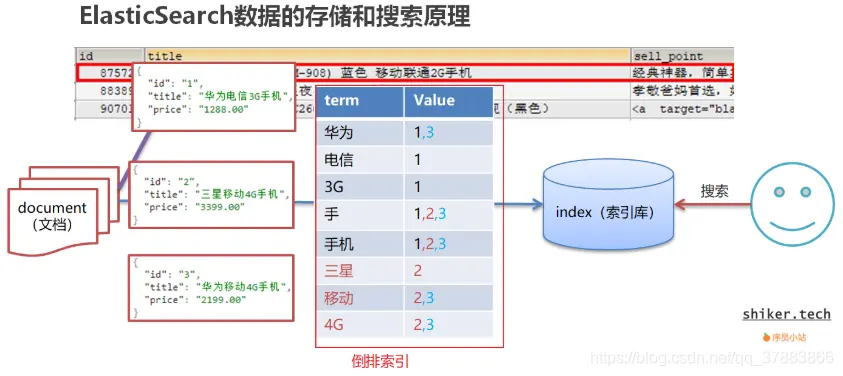
使用“手机”作为关键字查询
生成的倒排索引中,词条会排序,形成一颗树形结构,提升词条的查询速度
两种搜索方式的区别
结构化数据存储在关系型数据库中,通过构建二维表和索引完成对应数据的搜索
非结构化数据的搜索有两种,顺序扫描和全文搜索
顺序扫描:通过文字名称也可了解到它的大概搜索方式,即按照顺序扫描的方式查询特定的关键字
全文搜索:将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。
倒排索引
倒排索引:将文档进行分词,形成词条和文档的对应关系即为反向索引。
倒排索引的示例:
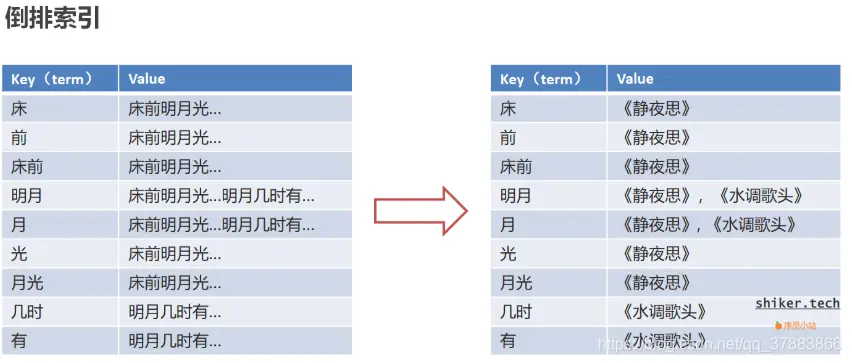
倒排索引由两部分组成:词典(上述case中的key)和倒排表(上述中的value)。
词典的常用数据结构
| 数据结构 | 优缺点 |
|---|---|
| 数据结构 | 优缺点 |
| 排序列表 | 实现简单,性能差 |
| 哈希表 | 性能高,内存消耗大 |
| 跳跃表 | 占用内存小,且高度可调,对模糊查询支持不好 |
| B树 | 磁盘索引,更新方便,检索速度较慢 |
| 字典树 | 查询效率跟字符长度有关,但只适合英文词典(中文需要用到双数组字典树) |
| 有限状态转换器(FST) | 共享前缀,内存消耗小,要求输入有序,更新困难 |
Lucene内部使用FST实现词典结构,内存占用小,查询速度快。
倒排表结构采用Frame of reference ,主要特性为数据压缩和跳跃表加速合并
客户端介绍
ES的4种客户端
到目前为止,ES有4种客户端,分别是:Jest client、Rest client、Transport client、Node client,相信大家在项目集成中选择客户端比较纠结,搜索案例的时候一会是这个客户端实现的,一会儿又是别的客户端实现的,自己又不了解每个客户端的优劣势,但又想集成最好的,下面就来说说各个客户端的区别,以及优劣势
| 客户类型 | 协议类型 | 说明 |
|---|---|---|
| Jest client | HTTP协议 | 非官方支持,但是使用广泛,ES集群使用不同的ES版本,使用原生ES API会有问题,而Jest不会,所以使用JestClient兼容性优于RestClient |
| Rest client | HTTP协议 | ES5.0之后官方发布Rest client,并大力推荐。有两个版本:Java Low Level REST Client: 低级别的REST客户端,通过http与集群交互,用户需自己编组请求JSON串,及解析响应JSON串。**兼容所有ES版本****Java High Level REST Client:高级别的REST客户端,基于低级别的REST客户端,增加了编组请求JSON串、解析响应JSON串等相关api。使用的版本需要保持和ES服务端的版本一致,否则会有版本问题。**其设置了默认调优参数,若版本匹配,其性能会更加优秀。 |
| Transport client | Native Elasticsearch binary协议 | ES2.3之后弃用,Transport client是不需要单独一个节点,脱离在集群之外。 |
| Node client | Native Elasticsearch binary协议 | ES7.0之后弃用,Node client需要单独建立一个节点,连接该节点进行操作,该节点不能存储数据,也不能成为主节点。 |
Spring Boot集成ES
使用spring-data-elasticsearch时,对应的spring-boot和spring相关版本要求如下:
| Spring Data Release Train | Spring Data Elasticsearch | Elasticsearch | Spring Framework |
|---|---|---|---|
| 2024.1 (in development) | 5.3.x | 8.15.3 | 6.1.x |
| 2024.0 | 5.3.1 | 8.13.4 | 6.1.x |
| 2023.1 (Vaughan) | 5.2.x | 8.11.1 | 6.1.x |
| 2023.0 (Ullmann) | 5.1.x | 8.7.1 | 6.0.x |
| 2022.0 (Turing) | 5.0.x[1] | 8.5.3 | 6.0.x |
| 2021.2 (Raj) | 4.4.x[1] | 7.17.3 | 5.3.x |
| 2021.1 (Q) | 4.3.x[1] | 7.15.2 | 5.3.x |
| 2021.0 (Pascal) | 4.2.x[1] | 7.12.0 | 5.3.x |
| 2020.0 (Ockham) | 4.1.x[1] | 7.9.3 | 5.3.2 |
| Neumann | 4.0.x[1] | 7.6.2 | 5.2.12 |
| Moore | 3.2.x[1] | 6.8.12 | 5.2.12 |
| Lovelace | 3.1.x[1] | 6.2.2 | 5.1.19 |
| Kay | 3.0.x[1] | 5.5.0 | 5.0.13 |
| Ingalls | 2.1.x[1] | 2.4.0 | 4.3.25 |
es客户端配置参考上述配置。
spring data elastic search提供了三种构建查询模块的方式:
基本的增删改查:继承spring data提供的接口就默认提供
接口中声明方法:无需实现类。**spring data根据方法名,自动生成实现类,方法名必须符合一定的规则
接口只要继承 ElasticsearchRepository 类即可。默认会提供很多实现,比如 CRUD 和搜索相关的实现。类似于 JPA 读取数据。
支持的默认方法有:count(), findAll(), findOne(ID), delete(ID), deleteAll(), exists(ID), save(DomainObject), save(Iterable)。
接口的命名是遵循规范的。常用命名规则如下:
使用用例参考:https://blog.csdn.net/qq_38011415/article/details/112241548
命名规则参考官方文档:https://docs.spring.io/spring-data/elasticsearch/docs/current/reference/html/#repositories.namespace-reference
springboot对ES客户端的支持与实现
springboot支持基于http协议的两种客户端,jestClient 和 restClient。
直接使用restClient连接
引包:es的服务端版本是几,客户端版本就是几
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
代码示例
package com.ke.breeze.cashcow.birch.elasticsearch;
import clover.org.apache.commons.lang.StringUtils;
import lombok.extern.slf4j.Slf4j;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.nio.reactor.IOReactorConfig;
import org.elasticsearch.client.Node;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.Arrays;
import java.util.Objects;
/**
* @useages:
* @author:chengzi
**/
@Slf4j
@Configuration
public class ESClientConfig {
private static final int ADDRESS_LENGTH = 2;
private static final String HTTP_SCHEME = "http";
@Value("${elasticsearch.host}")
String ipAddress;
@Value("${elasticsearch.user}")
private String userName;
@Value("${elasticsearch.password}")
private String password;
@Value("${elasticsearch.connect-timeout:5000}")
private Integer connectTimeout;
@Value("${elasticsearch.read-timeout:5000}")
private Integer readTimeout;
@Value("${elasticsearch.thead-counts:5}")
private Integer threadCounts;
@Bean
public RestClientBuilder restClientBuilder() {
String[] split = ipAddress.split(",");
HttpHost[] hosts = Arrays.stream(split)
.map(this::makeHttpHost)
.filter(Objects::nonNull)
.toArray(HttpHost[]::new);
return RestClient.builder(hosts);
}
@Bean(name = "highLevelClient")
public RestHighLevelClient highLevelClient(@Autowired RestClientBuilder restClientBuilder){
//配置身份验证
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(userName, password));
restClientBuilder.setHttpClientConfigCallback(
httpClientBuilder -> httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider).setDefaultIOReactorConfig(
IOReactorConfig.custom().setIoThreadCount(threadCounts).build()));
//设置连接超时和套接字超时
restClientBuilder.setRequestConfigCallback(
requestConfigBuilder -> requestConfigBuilder.setSocketTimeout(readTimeout).setConnectTimeout(connectTimeout));
//设置监听器,每次节点失败都可以监听到,可以作额外处理
restClientBuilder.setFailureListener(new RestClient.FailureListener() {
@Override
public void onFailure(Node node) {
super.onFailure(node);
log.error(node.getHost() + "--->该节点失败了");
}
});
return new RestHighLevelClient(restClientBuilder);
}
private HttpHost makeHttpHost(String str) {
assert StringUtils.isNotEmpty(str);
String[] address = str.split(":");
if (address.length == ADDRESS_LENGTH) {
String ip = address[0];
int port = Integer.parseInt(address[1]);
log.info("ES连接ip和port:{},{}", ip, port);
return new HttpHost(ip, port, HTTP_SCHEME);
} else {
log.error("传入的ip参数不正确!");
return null;
}
}
}
查询示例
package com.ke.breeze.cashcow.birch.elasticsearch;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.TypeReference;
import com.ke.breeze.cashcow.birch.constant.Constants;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.reindex.DeleteByQueryRequest;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* @useages:
* @author: yinweicheng
* @date: 2022/3/28
* @Copyright (c) 2022, ke.com All Rights Reserved
**/
@Component
@Slf4j
public class ESClient<T> {
@Resource
private RestHighLevelClient client;
/**
* 添加数据
*
* @param content 数据内容
* @param index 索引
* @param id id
*/
public String addData(T content, String index, String id) {
String result = null;
try {
IndexRequest request = new IndexRequest(index).id(id).source(JSON.toJSONString(content), XContentType.JSON);
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
result = response.getId();
log.info("索引:{},数据添加,返回码:{},id:{}", index, response.status().getStatus(), result);
} catch (IOException e) {
log.error("添加数据失败,index:{},id:{}", index, id);
}
return result;
}
/**
* 修改数据
*
* @param content 修改内容
* @param index 索引
* @param id id
*/
public String updateData(T content, String index, String id) {
String result = null;
try {
UpdateRequest request = new UpdateRequest(index, id).doc(JSON.parseObject(JSON.toJSONString(content)).getInnerMap());
UpdateResponse response = client.update(request, RequestOptions.DEFAULT);
result = response.getId();
log.info("数据更新,返回码:{},id:{}", response.status().getStatus(), result);
} catch (IOException e) {
log.error("数据更新失败,index:{},id:{}", index, id);
}
return result;
}
/**
* 批量插入数据
*
* @param index 索引
* @param list 批量增加的数据
*/
public String insertBatch(String index, List<ESEntity<T>> list) {
String state = null;
BulkRequest request = new BulkRequest();
list.forEach(item -> request.add(new IndexRequest(index)
.id(item.getId()).source(JSON.toJSONString(item.getData()), XContentType.JSON)));
try {
BulkResponse bulk = client.bulk(request, RequestOptions.DEFAULT);
int status = bulk.status().getStatus();
state = Integer.toString(status);
log.info("索引:{},批量插入{}条数据成功!", index, list.size());
} catch (IOException e) {
log.error("索引:{},批量插入数据失败", index);
}
return state;
}
/**
* 根据条件删除数据
*
* @param index 索引
* @param builder 删除条件
*/
public void deleteByQuery(String index, QueryBuilder builder) {
DeleteByQueryRequest request = new DeleteByQueryRequest(index);
request.setQuery(builder);
//设置此次删除的最大条数
request.setBatchSize(1000);
try {
client.deleteByQuery(request, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("根据条件删除数据失败,index:{}", index);
}
}
/**
* 根据id删除数据
*
* @param index 索引
* @param id id
*/
public String deleteById(String index, String id) {
String state = null;
DeleteRequest request = new DeleteRequest(index, id);
try {
DeleteResponse response = client.delete(request, RequestOptions.DEFAULT);
int status = response.status().getStatus();
state = Integer.toString(status);
log.info("索引:{},根据id{}删除数据:{}", index, id, JSON.toJSONString(response));
} catch (IOException e) {
log.error("根据id删除数据失败,index:{},id:{}", index, id);
}
return state;
}
/**
* 根据条件查询数据
*
* @param index 索引
* @param startPage 开始页
* @param pageSize 每页条数
* @param sourceBuilder 查询返回条件
* @param queryBuilder 查询条件
*/
public List<T> searchDataPage(String index, int startPage, int pageSize,
SearchSourceBuilder sourceBuilder, QueryBuilder queryBuilder) {
SearchRequest request = new SearchRequest(index);
//设置超时时间
sourceBuilder.timeout(new TimeValue(120, TimeUnit.SECONDS));
//设置是否按匹配度排序
sourceBuilder.explain(true);
//加载查询条件
sourceBuilder.query(queryBuilder);
//设置分页
sourceBuilder.from((startPage - 1) * pageSize).size(pageSize);
log.info("查询条件为:" + sourceBuilder);
request.source(sourceBuilder);
try {
SearchResponse searchResponse = client.search(request, RequestOptions.DEFAULT);
long totalHits = searchResponse.getHits().getTotalHits().value;
log.info("共查出{}条记录", totalHits);
RestStatus status = searchResponse.status();
if (status.getStatus() == Constants.HTTP_SUCCESS_CODE) {
List<T> sourceList = new ArrayList<>();
for (SearchHit searchHit : searchResponse.getHits().getHits()) {
String sourceAsString = searchHit.getSourceAsString();
T t = JSON.parseObject(sourceAsString, new TypeReference<T>(){});
sourceList.add(t);
}
return sourceList;
}
} catch (IOException e) {
log.error("条件查询索引{}时出错", index);
}
return null;
}
}



评论区